소프트웨어 엔지니어로서 새로운 패러다임을 마주하고 이를 실제 프로덕션 코드로 구현하는 과정은 언제나 치열한 자기 반성을 동반하게되는데요.(저만 그런가요…) 사실 고백하자면, 이번 Bastion-RAG 프레임워크의 두 번째 코어 거버넌스 레이어인 Vault 모듈을 설계하면서 저는 아주 부끄러운 아키텍처적 착각에 빠졌었습니다.
전통적인 RDBMS 모놀리식 아키텍처나 대규모 웹 애플리케이션 개발 관성에 오랜 기간 길들여져 있던 구시대적 개발자였기 때문일까요? 저는 처음에 멀티테넌시(Multi-Tenancy)를 그저 조금 복잡한 형태의 ‘유저별/역할별 권한 제어(RBAC/ABAC)’ 정도로 판단해 완전히 헤맸었습니다. “테넌트 ID 필드를 테이블에 하나 파고, 유저가 로그인할 때 세션이나 JWT에서 그 ID를 꺼내와 데이터베이스 쿼리 조건절에 WHERE tenant_id = ?만 에러 없이 잘 붙여주면 격리가 끝나는 것 아닌가?” 하고 생각했던 것입니다.
개념이 모호했던 것인지, 제가 최신 AI 아키텍처의 위협 요소를 명확하게 정의하고 있지 않은 것인지 혼란스러워 한참을 고민했습니다. 사실 처음 봤을 때는 ‘이미 기존 웹 서비스의 API 게이트웨이 단에서 토큰 검증이나 세션 분리를 다 처리하고 파이프라인으로 진입할 텐데, 내부 파이프라인 최전방로에서 이 멀티테넌시 격리 과정이 왜 또 필요하지?’ 라고 한참을 생각했습니다. 거대 언어 모델(LLM) 엔진 자체는 전역적으로 고정되어 있고 변경되지 않으니, 맨 뒤쪽 검색 엔진(Navigator)단에서 데이터베이스의 논리적 파티셔닝(Logical Partitioning)을 이용해 인덱스 컬렉션만 잘 쪼개어 조회하면 완벽히 격리될 것이라 착각한 것입니다.
지식의 모호함을 지우고, 테넌트 격리를 단순한 ‘애플리케이션 소스 코드 로직’이 아닌 ‘인프라 및 암호학적 최우선 제약 조건’으로 재정의하고 나서야 비로소 해결의 실마리가 보이기 시작했습니다. 유저의 쿼리가 Bastion-RAG 파이프라인에 진입하는 순간, 시스템이 가장 먼저 수행해야 하는 작업은 무엇일까요? 대다수의 일반적인 RAG 시스템이 입력 문장의 ‘의미(Semantic)’를 파악하고 벡터 DB를 룩업하는 데만 집중하지만, 엔터프라이즈 급 가혹한 거버넌스 환경에서 그보다 훨씬 중요한 것은 유입된 요청의 신원(Identity), 적합성(Format), 그리고 신선도(Freshness)를 완벽하게 증명하고 데이터를 암호학적으로 완전히 격리하는 일입니다.
아무리 뒤쪽의 검색 엔진단에서 논리적 파티셔닝과 벡터 컬렉션 분리를 강력하게 구축해 두었더라도, 그 앞단인 진입로와 비식별화 단계에서 데이터가 오염되거나 권한 외 영역의 메타데이터를 탐색할 수 있다면 격리 구조는 무의미해집니다. Vault 모듈은 하위 검색 모듈이 연산을 시작하기 전, 유입된 엔벨로프를 전수 검사하여 잘못되거나 변조된 요청을 입구에서 원천 차단하고 암호학적 격리를 집행하도록 기획되었습니다.
본 포스트에서는 런타임 오버헤드를 최소화하기 위한 최적화 설계와 Vault 멀티테넌시의 4대 격리 아키텍처 및 검증 컴포넌트의 기술 명세를 분석해보겠습니다. 사실 이 포스트에서 많은 부분이 메타데이터 필터링을 다시 설명하고 있긴합니다. 그래야 정밀 검증된 데이터를 기반으로 Vault가 완벽한 암호학적 격리를 할 수 있기 때문입니다.

URL Site > https://github.com/zafrem/bastion-vault
시리즈명 : Bastion-RAG – Project 보안 RAG
- [Bastion-RAG] Project 보안 RAG
- [Bastion-RAG 0] Get help from AI (아키텍처 설계)
- [Bastion-RAG 1 – Sentinel]
- [Bastion-RAG 2 – Vault]
- 멀티테넌시 – Here!
- 결정적 비식별화
- [Bastion-RAG 3 – Navigator]
- 하이브리드 리랭킹
- 논리적 파티셔닝
- [Bastion-RAG 4 – Archor]
- 임베딩 노이즈 주입
- 임베딩 모델 편향성 검증
- [Bastion-RAG 5 – Tracker]
- 데이터 리니지 추적
- Honey-token 주입
- [Bastion-RAG Demo]
목차
단일 컴퓨팅 인프라를 수많은 기업 고객사가 공유하여 사용하는 엔터프라이즈 SaaS(Software as a Service) 환경에서 데이터 격리 무결성은 서비스 생존과 직결되는 필수 요구사항입니다. 특히 거대 언어 모델(LLM)과 기업 내부 데이터베이스를 결합하는 RAG(검색 증강 생성) 시스템은, 검색 엔진의 조건절 누락이나 라우팅 컨텍스트 오염으로 인해 타인의 데이터 조각(Context)이 프롬프트 내에 섞여 들어가는 치명적인 교차 테넌트 데이터 유출(Cross-Tenant Exposure) 리스크에 상시 노출되어 있습니다.
많은 개발자가 멀티테넌시를 단순한 웹 애플리케이션 레벨의 유저 세션 분리나 데이터베이스 조회 쿼리의 WHERE tenant_id = ? 조건절 추가 정도로 안일하게 생각하여 파이프라인을 설계하다가 거대한 보안 공백을 마주하곤 합니다. Bastion-RAG 프레임워크의 코어 데이터 보호 레이어인 Vault 모듈(internal/tenant/, internal/tokendb/, internal/access/, internal/output/)은 이러한 소스 코드 레벨의 단일 장애점(SPOF) 위험을 원천 배격하기 위해 설계되었습니다.
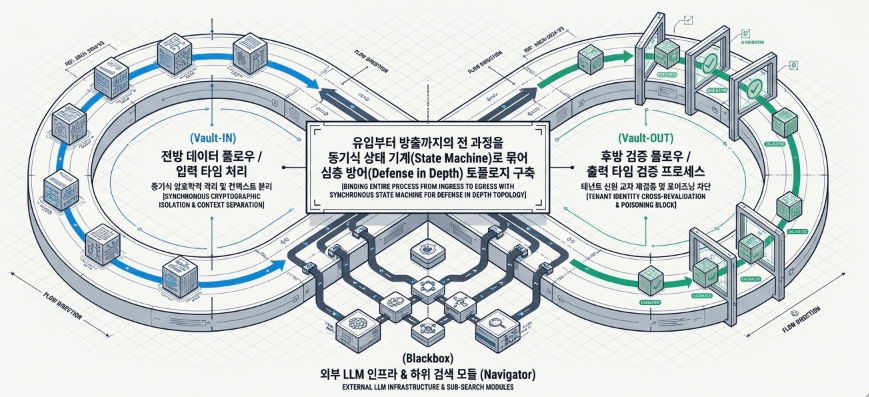
Vault 모듈은 단순히 특정 ‘소프트웨어 부품(모듈)’의 정적 기능에만 의존하지 않습니다. 유저의 요청이 최초 진입하는 순간부터 최종 답변으로 가공되어 나가는 순간까지, 파이프라인의 전 과정을 동기식 데이터 제어 프로세스로 묶어 테넌트 신원을 단계별로 교차 재검증(Re-check)하는 심층 방어(Defense in Depth) 프로세스 토폴로지를 집행합니다.
본 포스트에서는 데이터가 유입되어 비식별화 처리를 거치는 Vault-IN (Phase 1) 프로세스와 검색된 데이터셋의 무결성을 전수 스캔하여 최종 뷰를 생성하는 Vault-OUT (Phase 2) 프로세스의 단계별 데이터 실행 흐름 및 기술적 메커니즘을 심층 분석합니다.
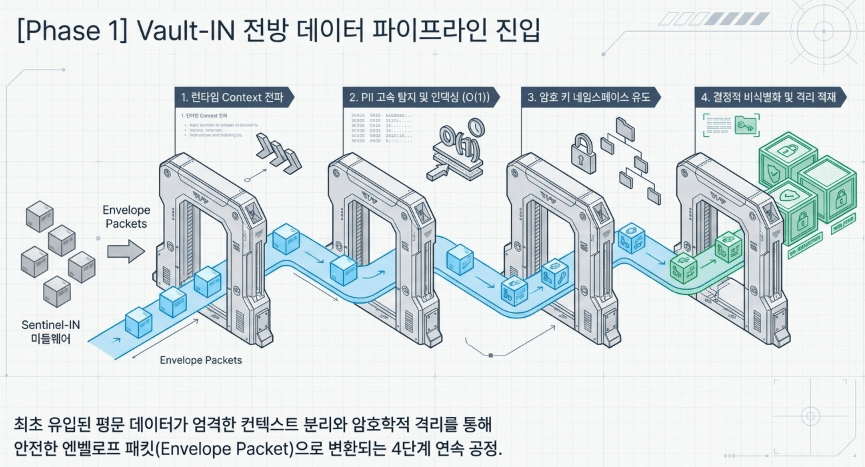
1. 전방 데이터 플로우: Vault-IN (Phase 1) 입력 타임 처리 프로세스
유저가 던진 자연어 질의(Query)와 메타데이터 인덱스 엔벨로프 패킷이 최전방 가드레일 미들웨어인 Sentinel-IN을 통과하는 즉시, Vault-IN 파이프라인이 동기식 상태 기계(State Machine) 형태로 구동을 시작합니다. 이 과정은 유입된 평문 데이터를 하위 모듈이 안전하게 처리할 수 있도록 컨텍스트를 분리하고 암호학적 격리를 집행하는 전방 처리 경로입니다.
[유저 요청 및 엔벨로프 패킷 진입]
│
▼
1.1 런타임 Context 전파 프로세스 ──────▶ tenant.WithTenant(ctx, tenantID) 박제
│
▼
1.2 PII 고속 탐지 및 인덱싱 프로세스 ──▶ Index 0 레코드 기반 스키마 맵 빌드 (O(1))
│
▼
1.3 암호 키 네임스페이스 유도 프로세스 ▶ masterKeyID = "tenant:{id}:category:{cat}" 파생
│
▼
1.4 결정적 비식별화 및 저장소 격리 ──▶ storeKey = tenantID + ":" + token 복합 키 적재
│
▼
[Vault-IN 전방 프로세스 종료] ─────────▶ Navigator(검색 모듈) 컨테이너 계약 페이로드로 이관
1.1 런타임 컨텍스트 전파 프로세스 (Context Propagation)
- 프로세스 입력:
Sentinel-IN레이어의 정적 규격 검증을 100% 무결하게 도과한 안전한tenant_id문자열 변수. - 상태 변환 및 매커니즘:
Vault-IN파이프라인은 진입 즉시tenant.WithTenant(ctx, tenantID)헬퍼 함수를 기동하여 Go 언어의 정적context.Context메모리 공간 내부에 테넌트 식별자를 바인딩합니다.
Go
// internal/tenant/isolation.go
type contextKey string
const tenantContextKey contextKey = "tenant"
func WithTenant(ctx context.Context, tenantID string) context.Context {
return context.WithValue(ctx, tenantContextKey, tenantID)
}
func FromContext(ctx context.Context) (string, bool) {
id, ok := ctx.Value(tenantContextKey).(string)
return id, ok
}
- 엔지니어링 제약 조건: 이 레이어의 기술적 본질은 테넌트 키 타입을 일반 평문 문자열(
"tenant")이 아니라 외부 패키지에서 절대로 접근하거나 오버라이드할 수 없는 패키지 내부 전용 정적 캡슐화 타입(type contextKey string)으로 선언한 점입니다. 이를 통해 다운스트림 전개 과정에서 수많은 서드파티 오픈소스 라이브러리나 외부 프록시 객체와의 데이터 결합/컨텍스트 병합 연산 시 발생할 수 있는 의도치 않은 네임스페이스 충돌 및 악의적인 세션 키 위변조 가능성을 구조적인 메모리 단에서 완벽하게 차단합니다. 만약 컨텍스트 내에 정당한 테넌트 토큰 주입이 유실된 채 핸들러가 가동되면, 시스템은 이를 디폴트(Default) 테넌트로 매핑하지 않고 즉각 무조건적인Authentication Failure예외를 선언하며 실행 흐름을 폐쇄합니다.
1.2 PII 고속 탐지 및 인덱싱 프로세스 (Detection Indexing)
- 상태 변환 및 매커니즘: 대규모 실시간 분산 트래픽 환경(최대 1,000건의 배치 레코드 묶음)에서 요청 내에 포함된 모든 문자열 청크 데이터를 전수 전사하여 머신러닝 분류기(
Classifier)를 연속 구동하는 구조는 연산 지연(Latency)의 주범이 됩니다.Vault-IN프로세스는 이 레이턴시 병목을 제어하기 위해 배치의 구조적 균일성(Homogeneous Schema)을 전제로 정적 샘플링 인덱싱 모델을 집행합니다.
Go
// internal/anonymizer/engine.go
func (e *Engine) buildDetectionIndex(records []map[string]any, policies []fieldPolicy) map[string]fieldPolicy {
index := make(map[string]fieldPolicy)
if len(records) == 0 { return index }
// 전체 배치 중 오직 첫 번째 레코드(Index 0)만 무거운 분류기 추론 엔진에 주입
detections := e.classifier.DetectPII(records[0])
// 탐지된 고유식별정보(PII) 속성 명세를 사전에 정의된 카테고리 정책 매트릭스와 교차 대조
for _, det := range detections {
for _, pol := range policies {
if pol.piiType == det.PIIType {
index[det.Field] = pol // 필드명을 해시 키로 삼아 O(1) 정적 룩업 맵 레이아웃 빌드
break
}
}
}
return index
}
- 엔지니어링 제약 조건: 오직 배치의 첫 번째 레코드(
records[0])만DetectPII지능형 추론을 거치며, 여기서 획득한 필드별 타겟 매핑 구조(Field → PII_Type → Strategy)를 해시 맵 인덱스로 고정 상주 시킵니다. 후속하는 나머지 999개의 모든 레코드들은 무거운 분류기 연산을 전면 스킵하고 본 정적 인덱스 명세를 그대로 상속받아 평문 필드 매핑 룩업 연산만 수행하므로, 전체 배치 변조 연산 비용을 기하급수적으로 낮추는 고속 최적화를 구현합니다.
1.3 암호 키 네임스페이스 유도 프로세스 (Key Derivation Sequence)
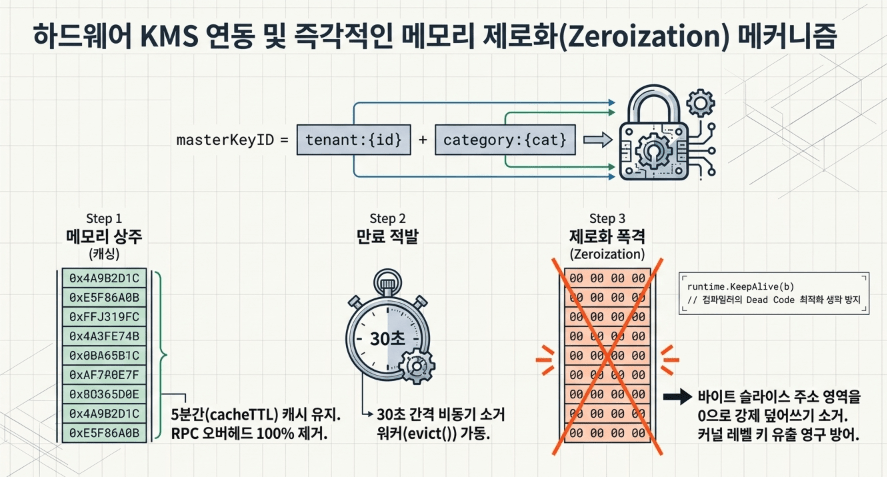
- 상태 변환 및 매커니즘: 컨텍스트 메모리 스페이스에서 안전하게 상속된 테넌트 토큰 식별자와 사용자가 타겟으로 지정한 데이터 자산 민감도 카테고리(DC-01: 고객 데이터, DC-03: 인사/재무 데이터 등)를 유기적으로 바인딩하여, 하드웨어 KMS(Key Management Service) 연동을 위한 복합 마스터 키 식별자(
masterKeyID)를 동적 파생합니다.$$\text{masterKeyID} = \text{fmt.Sprintf(“tenant:\%s:category:\%s”, tenantID, string(cat))}$$이 파생된 고유 ID를 기반으로 KMS 매니저 엔진을 기동하여 해당 테넌트 링 공간 전용의 결정적 HMAC 키와 대칭 키 암호화용 데이터 암호화 키(DEK) Plaintext를 메모리 내부에 정적으로 상주 시킵니다.
Go
// internal/kms/manager.go
func (m *Manager) GetOrGenerateDEK(ctx context.Context, masterKeyID, cacheKey string) (*DataKey, error) {
if dk := m.fromCache(cacheKey); dk != nil {
return dk, nil // 캐시 히트 시 물리적 KMS 하드웨어 원격 호출(RPC) 오버헤드를 100% 제거
}
dk, err := m.generateWithFailover(ctx, masterKeyID)
if err != nil {
return nil, err
}
m.toCache(cacheKey, dk) // cacheKey는 tenant × category 레벨로 완벽히 격리 바인딩
return dk, nil
}
- 엔지니어링 제약 조건: 연산 효율성을 위해 암호화 키 평문 데이터를 메모리에 5분간 캐싱하되(
cacheTTL), 백엔드에서 30초 간격으로 상시 가동되는 비동기 잔존 소거 워커(evict())에 의해 만료 시간이 적발되는 순간, 커널 레벨 메모리 덤프나 사이드 채널 공격으로 키 유출 취약점이 발생하는 것을 영구 원천 방어하기 위해 해당 바이트 슬라이스 주소 영역의 모든 값을0으로 강제 덮어쓰기 소거하는 메모리 제로화(Zeroization) 기법을 철저하게 집행합니다.
Go
func zeroize(b []byte) {
for i := range b {
b[i] = 0
}
// 컴파일러의 Dead Code Elimination(데드 코드 최적화 생략)에 의해
// 본 루프 연산이 누락되는 현상을 방지하기 위해 정적 킵얼라이브 강제 적용
runtime.KeepAlive(b)
}
1.4 결정적 비식별화 및 토큰 데이터베이스 적재 프로세스
- 상태 변환 및 매커니즘: 주입된 테넌트별 암호학적 키 소스를 바탕으로
deterministic_tokenization,hmac_sha256,partial_masking,encryption등 8대 가공 전략 인터페이스를 병렬 구동하여 원본 문자열을 완벽한 비식별 토큰 데이터로 영구 치환합니다. 이때 가변 역복원이 필요한 토큰화 대상 필드는 영구 매핑 저장소 레지스트리인TokenDB에 동기식으로 적재를 완료해야 합니다. - 격리 제약 조건:
TokenDB적재 및 조회 시 가동되는 인메모리 맵 및 프로덕션 RLS(Row-Level Security) PostgreSQL 데이터베이스 인덱스의 해시 검색 키는 언제나storeKey = tenantID + ":" + token형태로 강력하게 결합되어 생성됩니다. 이 복합 결합 구조 덕분에 비록 다른 테넌트 간에 완전히 동일한 평문 데이터가 입력되어 내부 해시 알고리즘 결과의 충돌 가능성이 발생하더라도, 접두사(Prefix) 영역에서 검색 범위 자체가 물리적인 인덱스 스캔 단계부터 원천 격리되므로 타 테넌트의 저장 스페이스 영역은 단 1바이트도 터치하지 못하는 완벽한 저장소 분리를 달성하게 됩니다.
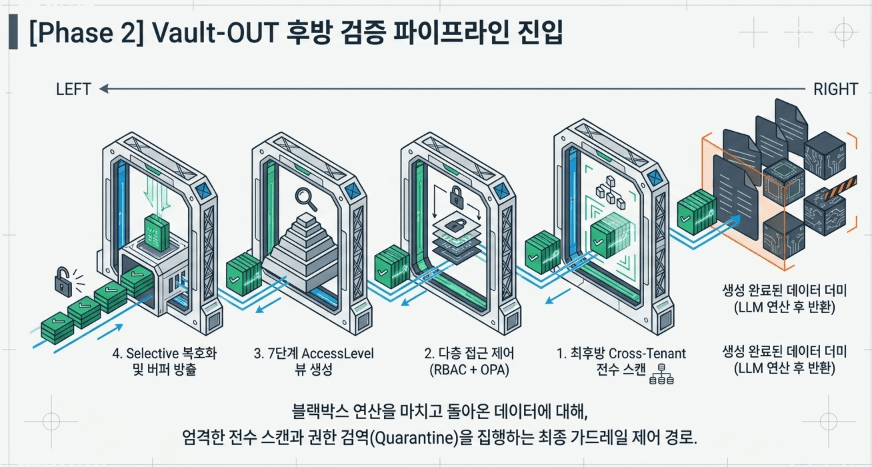
2. 후방 데이터 플로우: Vault-OUT (Phase 2) 출력 타임 검증 프로세스
하위 분산 검색 모듈인 Navigator가 물리적으로 격리된 벡터 데이터베이스 컬렉션을 스캔하여 관련 컨텍스트 청크를 룩업하고, 외부 상용 LLM 인프라망을 안전하게 통과하여 사용자에게 반환할 최종 답변 문장 셋을 완성해 내면, 파이프라인의 출구가 완전히 열리기 직전 최후방 방어선인 Vault-OUT 프로세스가 동기식으로 가동됩니다. 이 과정은 LLM의 블랙박스 연산 변형이나 하위 DB의 논리적 파티셔닝 오작동으로 인한 타인 데이터 유출을 차단하는 최종 가드레일 제어 경로입니다.
[다운스트림 Navigator 및 생성 완료 데이터 풀 유입]
│
▼
2.1 최후방 Cross-Tenant Verifier 스캔 ──▶ O(N) 전수 헤더 검증 및 오염율(Ratio) 연산
│
├───► 오염율 > 10% (Data Poisoning 위험 적발)?
│ │
│ ▼ [CRITICAL 인시던트] 버퍼 즉시 제로화 소거 및 배치 영구 폐쇄 차단
│
▼ (오염율 ≤ 10% 정상 제어 경계 통과)
2.2 세분화된 접근 제어 (RBAC + OPA) ──▶ 부서/역할 매트릭스 룩업 및 선언형 OPA 정책 평가
│
▼
2.3 7단계 레벨 체계 뷰(View) 생성 ─────▶ AccessFull부터 AccessAuditLog까지 필드 단위 마스킹 붕괴
│
▼
2.4 Selective 토큰 복호화 및 방출 ───▶ 명확한 Justification 증명 시에만 복호화 후 캐시 Zeroization
│
▼
[최종 클린 엔벨로프 유저 전송 반환]
2.1 최후방 Cross-Tenant Verifier 검증 프로세스
- 상태 변환 및 매커니즘: 하위 데이터베이스 아키텍처나 파이프라인 컴포넌트의 버그, 혹은 악의적인 간접 프롬프트 인젝션 공격에 의해 결과 데이터셋 내에 다른 테넌트의 소유 레코드가 섞여 들어왔을 최악의 인프라 붕괴 시나리오를 물리적으로 탐지 및 도려내는 최후방 백스톱(Final Backstop) 감사 제어 프로세스입니다.
- 격리 제약 조건: 유입된 모든 문서 배열 데이터를 대상으로 각 레코드 헤더에 각인된 고유
TenantID메타데이터 값을 세션 컨텍스트의userTenantID값과 $O(N)$으로 1:1 대조하는 동기식 전수 고속 스캔을 집행합니다.
Go
// internal/output/cross_tenant.go
const crossTenantSuspiciousRatio = 0.10
func (v *CrossTenantVerifier) Verify(
ctx context.Context,
records []model.DataRecord,
userTenantID string,
) ([]model.DataRecord, error) {
if userTenantID == "" {
return nil, fmt.Errorf("cross-tenant verifier: empty user tenant_id")
}
out := make([]model.DataRecord, 0, len(records))
mismatched := 0
for _, rec := range records {
if rec.TenantID == userTenantID {
out = append(out, rec)
continue
}
mismatched++
// 보안 관제 관제 센터(SOC) 모니터링을 위해 CRITICAL 하이 레벨 위반 로그 강제 발행
log.Printf("CRITICAL vault-out cross_tenant_violation: record_id=%s record_tenant=%s user_tenant=%s",
rec.RecordID, rec.TenantID, userTenantID)
}
// 타 테넌트 데이터 혼입 오염율이 전체 배치 규모의 10% 임계치를 넘어서면
// 시스템 데이터셋 포이즈닝(Poisoning) 상태로 선언하여 즉시 셧다운
if mismatched > 0 && float64(mismatched)/float64(len(records)) > crossTenantSuspiciousRatio {
return nil, fmt.Errorf("cross-tenant verifier: execution halted, poisoned batch refused")
}
return out, nil
}
- 의사결정 매트릭스: 스캔 도중 식별자 불일치 아노말리가 포착되면 해당 비정상 레코드를 결과 슬라이스에서 즉각 Pruning(가지치기 제거)하고 무해한 무결 서브셋 배열만 빌드합니다. 그러나 만약 혼입된 오염율이 전체 배치 크기의 10% 임계치(
crossTenantSuspiciousRatio)를 단 1비트라도 초과하는 순간,Vault-OUT프로세스는 이를 단순한 캐시 오염이 아닌 인프라망 전체가 장악당한 심각한 보안 침투 사건으로 판정합니다. 그 즉시 현재 트랜잭션과 연동된 모든 메모리 출력 텍스트 버퍼를 실시간으로 영구 소거(Zeroization)하고, 유효한 정상 레코드마저 전량 외부 반환을 거부하며 배치를 통째로 폭사(Refusing Batch)시켜 외부 데이터 유출 경로를 원천 차단합니다.
2.2 세분화된 접근 제어 프로세스 (RBAC + OPA Compliance)
- 상태 변환 및 매커니즘: 크로스 테넌트 스캔을 무결하게 통과한 클린 서브셋 자산은 사용자의 세부 소속 부서와 역할 그룹 매트릭스 사양에 부합하는지 2차 검증을 받게 됩니다.
marketing:analyst,hr:manager등 유저 식별 토큰의"{department}:{role}"문자열 키를 기반으로 내장 RBAC 매트릭스를 고속 룩업합니다. - 엔지니어링 제약 조건: 중앙 집중형 OPA(Open Policy Agent) 정책 엔진이 통합 연동되어 가동 중인 환경이라면 Rego 정책 선언 규칙셋을 동기식 호출하여 최종 인가 판정을 위임하되, 만약 네트워크 단절이나 OPA 인프라 노드 다운 등의 비상 상황이 발생하면 인프라 가용성 확보를 위해 사전에 정의된 내장 로컬 RBAC 등급을 최상위 천장(Ceiling) 규칙으로 자동 드롭백 시키는 Fail-open Fallback 아키텍처를 집행하여 시스템 마비를 예방합니다. 또한, 데이터 활용 목적 제약 조건 행렬(
purposeMatrix)을 결합 평가하여, 인가된 부서의 정당한 유저일지라도 현재 호출 목적 사양이 컴플라이언스 규칙(예:PurposeTrainingData목적 유입 시 일반 경로 접근 원천 차단 및 Break-Glass 비상 승인 워크플로우 강제)을 위반할 경우 접근 권한 레벨을 즉각 최하위 등급인AccessNone으로 붕괴 강제 차단합니다.
2.3 7단계 AccessLevel View 필드 필터링 프로세스
- 상태 변환 및 매커니즘: 인가 평가가 완료되어 확정된 최종 권한 순위 지표인
AccessLevel랭크 스펙에 의거하여 레코드 내 모든 데이터 필드 자산의 추상화 가공 뷰(View) 레이아웃을 생성합니다.
Go
// internal/access/controller.go
func EnforceMinimumLevel(requested, allowed model.AccessLevel) model.AccessLevel {
// 유저가 임의로 상위 보기 옵션을 요청하더라도
// 사전에 인가 승인된 OPA/RBAC 상한선(Ceiling)을 넘지 못하도록 원천 제한
if model.AccessLevelRank(requested) > model.AccessLevelRank(allowed) {
return allowed
}
return requested
}
- 필드 단위 제어 변환: 랭크 스펙 등급(7단계:
AccessFull~ 1단계:AccessAuditLog)에 맞춰 필드 단위 데이터 매싱이 집행됩니다. 최상위 7등급 권한 유저에게는 원본 데이터 무결 전송 권한(AccessFull)을 부여하지만, 중간 등급인 4등급 권한 유저(AccessKAnonymized)에게는 수학적 준식별자 동질성이 확보되도록 상세 번지수가 탈락된 광역 행정구역 일반화 데이터 체계로 강제 다운그레이드 가공을 집행하여, 사용자 역할에 국한된 정보의 최소 노출(Data Minimization)을 실현합니다.
2.4 Selective 토큰 복호화 및 방출 프로세스
- 상태 변환 및 매커니즘:
AccessFull등급 권한과 명확한 복호화 정당성 사유 및 감사 추적 인덱스(FieldDisclosureTrail) 작성이 완료된 정당한 레코드에 한해서만, 메모리에 상주 중인 테넌트별 전용 DEK Plaintext 블록을 활용하여ENC:접두사 암호문 바이너리를 selective 복호화해 냅니다. - 프로세스 종료: 평문 데이터 복원 및 최종 엔벨로프 패킷 구성이 완료되어 호출자의 소켓 버퍼로 데이터 전송이 끝나는 즉시, 사용된 모든 임시 텍스트 스트림 버퍼와 메모리 캐시 엔트리는 청소 워커에 의해 영구 영(0)으로 덮어쓰기 소거(Zeroization)되며, 이로써 하나의 완전한 동기식 제로 트러스트 멀티테넌시 프로세스 사이클이 종료됩니다.
3. 핵심 요약: 모듈 독립성과 프로세스 연속성의 유기적 결합
Bastion-RAG 아키텍처가 전면 재설계를 거치며 정립한 핵심 거버넌스는 멀티테넌시를 특정 모듈의 정적 코드로 박제하지 않았다는 점에 있습니다. 유입 시점에 메타데이터 규격을 타이트하게 전수 검사하여 런타임 컨텍스트 및 KMS 암호 키 네임스페이스를 물리적으로 완전히 격리 분리해 내는 ‘전방 프로세스(Vault-IN)’와, 인프라망을 통과해 되돌아온 결과 배열 데이터셋의 테넌트 소유권을 $O(N)$으로 전수 대조하여 오염율 10% 초과 발생 시 데이터 버퍼 전체를 메모리상에서 강제 파쇄 폭사시키는 ‘후방 프로세스(Vault-OUT)’가 유기적으로 연속 결합되어 구동됨으로써, 인적 실수와 인프라 붕괴 시에도 기업의 핵심 지식 정보 자산을 방어하는 엔터프라이즈 거버넌스 가드레일을 완성해 가고 있습니다.