다양한 엔터프라이즈 인프라 보호와 거버넌스를 담당해 왔지만 패러다임 변화에 계속 적응 하기 위해서 노력을 하고 있습니다. 사실 최근에 들어서야 저는 대규모 언어 모델(LLM)과 검색 증강 생성(RAG) 보안은 단순한 시스템 프롬프트 가드레일 수준을 설계하고 있었습니다. 그러나 데이터 엔지니어링을 공부하는 입장에서 2026년 현재, AI 보안은 시스템의 가장 깊은 곳인 ‘데이터 엔지니어링 및 전처리 단계’에서 아키텍처적으로 설계되어야 된다고 생각을 했습니다.
저는 이러한 흐름 속에서 고도화된 AI 거버넌스의 정수를 공유하고자 [The AI Shield] 시리즈를 만들어보고 있습니다. 지난 포스팅들을 통해 실시간 프롬프트 인젝션 방어 설계와 메타데이터 필터링, 그리고 하이브리드 리랭킹을 통한 최종 검증 관문 구축을 다루었습니다. 이번 네 번째 포스팅에서는 엔터프라이즈 AI 보안의 아킬레스건이자 다중 사용자 환경의 핵심인 ‘멀티 테넌시(Multi-tenancy) 환경에서의 데이터 엔지니어링 및 전처리 설계’를 집중적으로 파헤쳐보고자 합니다.
많은 엔지니어들이 애플리케이션 레이어에서의 필터링만으로 사용자 간의 데이터를 격리할 수 있다고 착각하지만, 비결정론적으로 작동하는 AI 생태계에서는 전처리 단계에서부터 데이터 간의 물리적·논리적 격벽을 쌓지 않으면 대규모 데이터 유출 사고를 피할 수 없습니다. 본 가이드는 완벽한 멀티 테넌시 데이터 격리를 성취하기 위한 아키텍처적 초석을 제시합니다.

시리즈명: [The AI Shield] 고도화된 AI 보안과 데이터 거버넌스 아키텍처
- 시스템 설정 및 필터링
- 데이터 엔지니어링 및 전처리
- 멀티 테넌시 (Here!)
- 결정적 비식별화
- 데이터 리니지 추적
- 수학적 최적화 및 고도화된 방어
목차
1. AI 멀티 테넌시 데이터 격리의 구조적 위협과 패러다임 변화
전통적인 소프트웨어 아키텍처(SaaS)에서의 멀티 테넌시는 관계형 데이터베이스(RDB)의 테넌트 ID 필터링이나 스키마 분리만으로도 비교적 안전하게 유지될 수 있었습니다. 그러나 비정형 데이터와 벡터 검색을 기반으로 하는 현대 엔터프라이즈 AI 환경에서는 완전히 새로운 보안 위협이 발생합니다.
1.1. 크로스 테넌트 데이터 유출(Cross-Tenant Data Leakage)의 메커니즘
RAG 시스템이나 LLM 미세 조정(Fine-tuning) 파이프라인에서 여러 테넌트(고객사, 부서, 프로젝트 단위)의 데이터가 동일한 임베딩 모델을 거쳐 하나의 벡터 데이터베이스에 저장될 때 치명적인 위협이 시작됩니다.
공격자가 정교한 간접적 프롬프트 인젝션이나 의미론적 유사성 우회 기법을 사용할 경우, 모델은 사용자의 권한을 초월하여 다른 테넌트의 데이터 조각(Chunk)을 컨텍스트 윈도우에 로드할 수 있습니다. 이는 전통적인 하드코딩된 규칙으로는 탐지하기 불가능한 ‘의미론적 데이터 유출’을 야기합니다.
1.2. 공유 인덱스의 확률론적 붕괴 리스크
많은 엔터프라이즈 시스템이 비용 최적화를 위해 하나의 벡터 인덱스 내에 메타데이터로 테넌트를 구분하는 방식을 취합니다. 그러나 고차원 벡터 공간에서 HNSW(Hierarchical Navigable Small World) 알고리즘 등으로 인덱스를 탐색할 때, 필터링 로직이 벡터 검색 엔진의 심층 레이어와 유기적으로 결합되어 있지 않으면 근사 근접 이웃(ANN) 검색 과정에서 다른 테넌트의 데이터 영역으로 경계가 허물어지는 ‘인덱스 붕괴’ 현상이 발생할 수 있습니다. 따라서 데이터 전처리 단계에서부터 원천적인 격리 메커니즘을 설계하는 것이 필수적입니다.
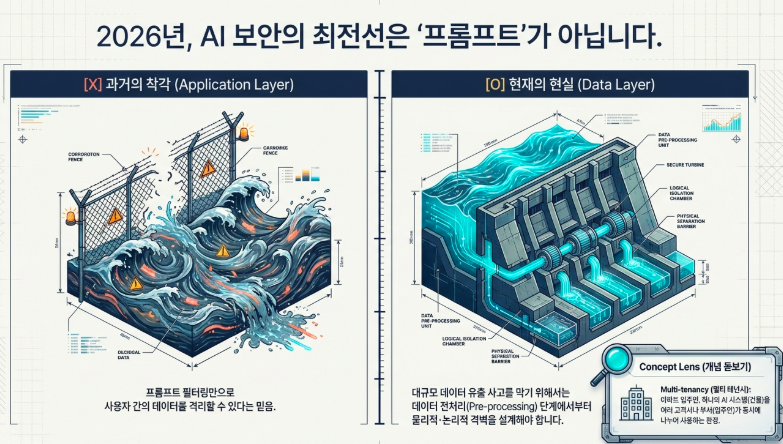
2. 데이터 전처리 및 수집 파이프라인에서의 격리 전략
성공적인 멀티 테넌시 아키텍처는 데이터가 시스템에 유입되는 최초의 순간인 데이터 전처리(Data Pre-processing) 및 수집(Ingestion) 파이프라인에서 결정됩니다.
2.1. 테넌트별 독립 인젝션 파이프라인(Isolated Ingestion Pipelines)
엔터프라이즈 환경에서는 공유 파이프라인 내에서 조건문으로 테넌트를 분기하는 방식을 지양해야 합니다. 대신, 아파치 카프카(Apache Kafka)나 AWS Kinesis 등의 메시지 브로커를 사용할 때 토픽 자체를 테넌트별로 엄격히 분리하거나, 쿠버네티스(Kubernetes) 기반의 휘발성 포드(Pod)를 테넌트별로 동적 생성하여 데이터 청킹(Chunking)과 파싱(Parsing)을 수행해야 합니다.
- 이점: 특정 테넌트의 문서 파싱 과정에서 악성 페이로드로 인해 전처리 엔진이 오염되거나 메모리 커널이 탈취되더라도, 타 테넌트의 파이프라인으로 위험이 전이되는 폭발 반경(Blast Radius)을 최소화할 수 있습니다.
2.2. 엔벨로프 암호화(Envelope Encryption) 기반의 데이터 전처리
데이터 거버넌스를 완성하기 위해 전처리된 모든 텍스트 청크와 임베딩 벡터는 테넌트 전용 KMS(Key Management Service) 키로 암호화되어야 합니다.
- 메커니즘: 데이터 엔지니어링 파이프라인은 원문 문서를 조각낸 후, 해당 테넌트의 고유 마스터 키로 생성된 데이터 암호화 키(DEK)를 사용해 청크를 암호화합니다.
- 보안적 특징: 벡터 데이터베이스나 스토리지 관리자가 물리적 디스크에 접근하더라도 복호화 키 권한이 없다면 타 테넌트의 지식 베이스를 절대 열람할 수 없는 제로 트러스트(Zero Trust) 상태를 유지하게 됩니다.
3. 벡터 데이터베이스의 멀티 테넌시 구현 모델 비교 분석
데이터 엔지니어가 RAG 시스템을 설계할 때 직면하는 가장 큰 기술적 갈림길은 벡터 데이터베이스 내에서 멀티 테넌시를 구현하는 아키텍처 모델의 선택입니다. 2025년과 2026년 가이드라인에 기반한 세 가지 핵심 모델을 심층 비교 분석합니다.
3.1. 물리적 격리 모델: 테넌트당 독립 인덱스 (Tenant-per-Index)
각 테넌트마다 물리적으로 완전히 분리된 벡터 인덱스 또는 전용 DB 인스턴스를 할당하는 방식입니다.
- 보안 신뢰성: 최상 (물리적으로 데이터가 섞이지 않음).
- 비용 및 운영 효율: 최악 (인프라 비용이 테넌트 수에 비례하여 기하급수적으로 증가하며, 빈번한 인덱스 생성 및 관리가 불가능함).
3.2. 논리적 격리 모델: 테넌트당 네임스페이스 (Namespace-per-Tenant)
하나의 데이터베이스 인스턴스 내에서 논리적인 격리 장벽인 네임스페이스(Namespace) 또는 파티션을 할당하는 방식입니다. Pinecone, Milvus, Qdrant 등 현대 엔터프라이즈 벡터 DB가 가장 권장하는 모델입니다.
- 보안 신뢰성: 우수 (데이터베이스 엔진 레벨에서 쿼리가 도달할 수 있는 인덱스 노드 자체를 사전에 격리함).
- 비용 및 운영 효율: 우수 (인프라 리소스를 공유하면서도 높은 수준의 격리를 유지할 수 있어 비용 효율적임).
3.3. 공유 인덱스 모델: 메타데이터 필터링 기반 (Metadata-driven Shared Index)
모든 테넌트의 데이터를 하나의 거대한 인덱스에 저장하고, tenant_id 메타데이터 속성만을 이용해 필터링 쿼리를 수행하는 방식입니다.
- 보안 신뢰성: 미흡 (애플리케이션 개발자의 코딩 실수나 임베딩 모델의 편향, 인덱스 검색 알고리즘의 한계로 인해 크로스 테넌트 유출 위험이 가장 높음).
- 비용 및 운영 효율: 최상 (가장 가볍고 관리가 용이함).
3.4. 멀티 테넌시 모델별 아키텍처적 특성 비교
| 평가 지표 | 물리적 격리 (Index-per-Tenant) | 논리적 격리 (Namespace-per-Tenant) | 공유 인덱스 (Metadata Filtering) |
| 보안 및 격리 수준 | 최상 (물리적 완벽 격리) | 우수 (엔진 레벨 논리 격리) | 낮음 (애플리케이션 의존적) |
| 인프라 비용 효율성 | 최악 (리소스 낭비 심각) | 우수 (합리적 리소스 공유) | 최상 (최적의 리소스 활용) |
| 확장성 (Scalability) | 낮음 (테넌트 증가 시 한계 발생) | 최상 (수만 개의 네임스페이스 관리 가능) | 우수 (대규모 데이터 통합 용이) |
| 엔지니어링 복잡도 | 높음 (인프라 프로비저닝 자동화 필요) | 중간 (표준 API 관리) | 낮음 (단일 인덱스 운영) |
4. 제로 트러스트 가드레일과 실시간 동적 권한 인지 제어
멀티 테넌시 데이터 엔지니어링이 성공적으로 안착하기 위해서는 런타임 환경에서의 제로 트러스트 제어 메커니즘이 연동되어야 합니다.
4.1. 컨텍스트 윈도우 진입 전 2차 검증(Post-Retrieval Verification)
데이터 격리는 벡터 DB에서 데이터를 꺼내오는 것으로 끝나지 않습니다. 데이터 파이프라인의 미들웨어 계층에서는 검색된 데이터 청크들이 현재 요청을 보낸 사용자의 테넌트 컨텍스트와 일치하는지 다시 한번 검증하는 내부 정책 엔진(Policy Gate)을 통과시켜야 합니다.
- 메커니즘: 벡터 DB가 리턴한 결과 오브젝트의 복호화 과정에서 사용자의 테넌트 키와 일치하지 않는 데이터가 발견되면 시스템은 즉시 무조건 기각(Hard Drop) 처리를 하고 SIEM 시스템에 임계치 초과 경고를 전송합니다.
4.2. 에이전틱 AI 환경에서의 동적 격리 경계(Dynamic Isolation Boundaries)
최근 주목받는 에이전틱 AI(Agentic AI) 시스템 환경에서는 AI가 스스로 다양한 도구(Tool)와 API를 호출하며 연쇄적인 작업을 수행합니다. 이때 테넌트 경계를 넘나들 수 없도록 각 에이전트 실행 런타임에 짧은 수명의 단기 토큰(Short-lived Tokens)을 발급하고 세션 수준에서 격리 경계를 가두는 구조적 방어 레이어가 반드시 선행 설계되어야 합니다.
5. 엔터프라이즈 데이터 거버넌스 및 실무 체크리스트
엔터프라이즈 환경에서 안전한 멀티 테넌시 데이터 시스템을 운영하기 위해서는 글로벌 표준 컴플라이언스(NIST AI RMF, ISO/IEC 42001, EU AI Act)의 요구사항을 명확히 충족해야 합니다.
5.1. 감사 추적(Audit Trail)과 데이터 리니지
멀티 테넌시 환경의 핵심 규제 준수 요건은 “특정 테넌트의 데이터가 다른 테넌트의 가시성에 절대로 영향을 미치지 않았음을 투명하게 입증하는 것”입니다. 이를 위해 모든 전처리 파이프라인의 로그와 벡터 검색 쿼리 로그에는 테넌트 ID가 암호화된 형태로 기록되어 사후 감사 및 데이터 리니지 추적의 근거로 활용되어야 합니다.
5.2. 데이터 보안 엔지니어를 위한 멀티 테넌시 10계명 체크리스트
성공적인 방어 아키텍처 설계를 위해 데이터 보안 담당자는 다음 항목을 정기적으로 감사해야 합니다:
- 파이프라인 격리: 테넌트별 수집 및 전처리 파이프라인이 논리적/물리적으로 분리되어 있는가?
- 네임스페이스 의무화: 벡터 DB 선택 및 설계 시 공유 인덱스를 지양하고 네임스페이스 격리 방식을 도입했는가?
- 암호화 분리: 각 테넌트의 데이터 청크가 고유한 KMS 마스터 키(DEK/KEK 구조)로 암호화되는가?
- 하드코딩 배제: 쿼리 생성 시 테넌트 ID가 미들웨어 레이어에서 자동으로 삽입되며 조작 불가능한 구조인가?
- 2차 검증 수행: 검색 결과가 LLM의 컨텍스트 윈도우에 주입되기 전 테넌트 일치 여부를 재검증하는가?
- 폭발 반경 통제: 문서 파싱 엔진이 컨테이너 샌드박스(gVisor 등) 환경 내에서 안전하게 격리되어 실행되는가?
- 최소 권한 제어: 에이전트 런타임에 단기 세션 토큰을 부여하여 타 테넌트 API 접근을 차단했는가?
- 데이터 파기 보장: 특정 테넌트 탈퇴나 계약 종료 시 해당 네임스페이스의 데이터를 완전히 삭제(Hard Delete)할 수 있는 아키텍처인가?
- 지속적 레드티밍: 자동화 도구(PyRIT 등)를 통해 테넌트 경계 우회 공격 시나리오를 주기적으로 테스트하는가?
- 감사 로그 통합: 모든 크로스 테넌트 접근 시도 로그가 엔터프라이즈 SIEM 체계에 통합되어 실시간 경보를 발생시키는가?
결론: 설계된 데이터 격리가 성취하는 엔터프라이즈 AI 신뢰성
멀티 테넌시 환경에서의 데이터 보호는 단순한 코딩 수준의 예외 처리가 아닌, 시스템의 기저인 데이터 엔지니어링 수준에서 완비되어야 하는 거 거대한 거버넌스 인프라입니다. 20년 동안 전통적인 인프라 보안의 격동기를 거치며 얻은 결론은, 사후에 덧붙여진 보안 방패는 진화하는 적대적 공격 시나리오 앞에 언제나 무력화된다는 사실입니다.
수집과 전처리 단계에서부터 철저하게 설계된 Defense in Depth(다층 방어 체계) 아키텍처만이 기업의 가장 소중한 자산인 데이터를 보호하고 생성형 AI의 비결정론적 리스크를 완벽하게 통제할 수 있습니다. 메타데이터와 네임스페이스의 경계를 정교하게 구축하는 이 과정이야말로, 현대 기업이 글로벌 규제를 준수하며 안전하게 비즈니스 혁신을 가속화하는 가장 확실한 이정표입니다.
다음 포스팅에서는 [The AI Shield] 시리즈의 다섯 번째 주제인 ‘데이터 엔지니어링 및 전처리: 결정적 비식별화’를 통해 민감 정보(PII)를 완벽하게 보호하면서도 데이터의 모델 가치를 보존하는 고도화된 전처리 전략을 생각해 보겠습니다.
사실 개인적으로 RDB에 익숙한 오래된 엔지니어면 AI 학습용 데이터나 RAG 데이터를 보면, 혼란을 느끼며 뭔가 분류를 해야된다는 생각을 하실껍니다. 하지만 이미 합쳐진 데이터를 분류하는건 힘들고, 수집시 부터 분류를 하기 위해 노력하겠지만 그럼 파인튜닝에서는 오버핏이 되면서 성능이 떨어지죠. RAG에서는 그래도 괜찮을거 같긴합니다. 그래서 사실 저는 아직 이 멀티 테넌트를 어느정도 해야 옳은지 잘모르겠습니다. 나중에 직접 구현해보고 이야기 드리도록 하겠습니다.