Having spent decades managing enterprise infrastructure protection and governance, I continuously strive to adapt to shifting technological paradigms. To be completely candid, until recently, I found myself designing AI security solely at the surface level—focusing primarily on system prompt guardrails for Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG). However, looking at this through the lens of data engineering in 2026, it has become abundantly clear that AI security must be built architecturally at the deepest layer of the system: the data engineering and pre-processing stage.
As part of this shift, I launched [The AI Shield] series to share advanced AI governance frameworks. In our previous posts, we explored real-time prompt injection defenses, metadata filtering, and establishing the final validation checkpoint via hybrid re-ranking. In this fourth installment, we will dive deep into the Achilles’ heel of enterprise AI security and the core of multi-user environments: Data Engineering and Pre-processing Design for Multi-Tenancy.
Relying exclusively on application-layer filtering to isolate tenant data introduces significant structural vulnerabilities within non-deterministic artificial intelligence ecosystems. Implementing data segregation solely at the application runtime level, without constructing physical and logical isolation boundaries during the initial data pre-processing stage, permits cross-tenant data exposure vectors via shared memory or context serialization failures.
To mitigate these exposure risks, multi-tenant enterprise architectures must enforce strict infrastructure-level boundaries before payloads reach the embedding models or retrieval engines.
Establishing an airtight multi-tenant environment requires isolating data ingestion pipelines, compute runtimes, and storage layers into distinct cryptographic or physical partitions. By embedding tenant-specific validation hashes and enforcing mandatory access boundary checks at the ingestion pre-processing phase, the system prevents unauthorized cross-tenant semantic mapping.

Series: [The AI Shield] Advanced AI Security and Data Governance Architecture
- System Configuration and Filtering
- Data Engineering and Preprocessing
- Multi-tenancy (Here!)
- Deterministic De-identification
- Data Lineage Trace
- Mathematical Optimization and Advanced Defense
Table of Contents
1. Structural Threats and Paradigm Shifts in AI Multi-Tenancy
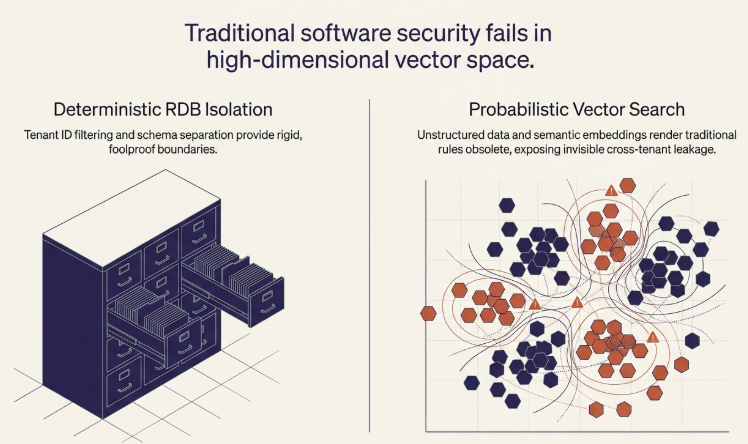
In traditional SaaS software architectures, multi-tenancy could be maintained relatively safely using simple tenant ID filtering or schema separation within relational databases (RDBs). However, modern enterprise AI systems built on unstructured data and vector searches expose entirely new threat vectors.
1.1. Mechanism of Cross-Tenant Data Leakage
When data from multiple tenants (such as distinct clients, departments, or project teams) passes through the same embedding model and is stored in a single vector database for a RAG system or fine-tuning pipeline, critical vulnerabilities emerge. If an attacker uses sophisticated indirect prompt injections or semantic similarity bypass techniques, the model can override user permissions and load another tenant’s data chunks into its context window. This causes a “semantic data leak” that traditional hardcoded rules fail to detect.
1.2. Probabilistic Collapse Risks of Shared Indexes
Many enterprise environments adopt a shared vector index model where tenants are distinguished purely by metadata fields to optimize infrastructure costs. However, when navigating high-dimensional vector spaces using algorithms like HNSW (Hierarchical Navigable Small World), the boundary lines can blur during Approximate Nearest Neighbor (ANN) search if the filtering logic is not natively integrated into the deepest layers of the vector search engine. This causes a “probabilistic index collapse,” making isolation at the pre-processing stage mandatory.
2. Isolation Strategies in Data Pre-processing & Ingestion Pipelines
A resilient multi-tenant architecture is won or lost at the earliest stage: the data pre-processing and ingestion pipeline.
2.1. Tenant-Specific Isolated Ingestion Pipelines
Enterprise systems must move away from using simple conditional branching within a shared ingestion pipeline. Instead, message brokers like Apache Kafka or AWS Kinesis should enforce strict topic separation per tenant, or dynamically spin up short-lived, ephemeral Kubernetes pods for each tenant to handle data chunking and parsing.
Architectural Benefit: If a malicious payload within a specific tenant’s document contaminates the parsing engine or compromises the memory kernel, the blast radius is tightly contained. This prevents the threat from spilling over into other tenants’ pipelines.
2.2. Envelope Encryption-Based Pre-processing
To solidify true data governance, all pre-processed text chunks and embedding vectors must be encrypted using tenant-specific KMS (Key Management Service) keys.
- The Mechanism: The data engineering pipeline slices the source document into chunks and immediately encrypts them using a Data Encryption Key (DEK) generated from the tenant’s unique master key.
- Security Characteristics: Even if a vector database administrator or an infrastructure manager gains physical access to the storage disks, they cannot view a tenant’s knowledge base without the corresponding decryption keys, maintaining a state of absolute Zero Trust.
3. Comparative Analysis of Multi-Tenancy Models in Vector Databases
When building a RAG architecture, data engineers face a critical technical fork in the road: how to implement multi-tenancy within the vector database. We compare three core models aligned with modern 2026 guidelines.
3.1. Physical Isolation: Tenant-per-Index
Allocating an entirely separate vector index or dedicated database instance to each tenant.
- Security Reliability: Highest (data streams never physically mix).
- Cost & Operational Efficiency: Lowest (infrastructure costs scale linearly with tenant counts, making rapid provisioning impractical).
3.2. Logical Isolation: Namespace-per-Tenant
Allocating logical walls called namespaces or partitions within a single database instance. This is the standard recommendation for modern vector DBs like Pinecone, Milvus, and Qdrant.
- Security Reliability: High (the database engine natively isolates index nodes before queries execute).
- Cost & Operational Efficiency: High (allows shared infrastructure resources while keeping an algorithmic separation barrier).
3.3. Shared Index Model: Metadata-Driven Filtering
Storing all tenant data in one massive index and running filtering queries based strictly on a tenant_id attribute.
- Security Reliability: Low (vulnerable to developer coding errors, embedding model drift, or index bypass techniques).
- Cost & Operational Efficiency: Highest (highly lightweight and trivial to manage).
3.4. Architectural Trade-offs by Multi-Tenancy Model
| Evaluation Metric | Physical Isolation (Index-per-Tenant) | Logical Isolation (Namespace-per-Tenant) | Shared Index (Metadata Filtering) |
| Security & Isolation Level | Highest (Complete Physical Isolation) | High (Engine-Level Logic Isolation) | Low (Application-Dependent) |
| Infrastructure Cost Efficiency | Lowest (Severe Resource Waste) | High (Optimized Resource Sharing) | Highest (Maximum Resource Utilization) |
| Scalability | Low (Bottlenecks as Tenants Scale) | Highest (Manages Tens of Thousands of Namespaces) | High (Scales Easily to Large Datasets) |
| Engineering Complexity | High (Requires Automated Provisioning) | Moderate (Standard API Configurations) | Low (Single Index Operations) |
4. Zero Trust Guardrails & Real-Time Dynamic Authorization Control
Multi-tenancy data engineering must be backed by runtime Zero Trust control mechanisms to remain secure.
4.1. Post-Retrieval Verification
Data isolation does not stop at pulling records from the vector DB. The middleware layer of the data pipeline must pass retrieved data chunks through an internal policy engine (Policy Gate) to verify a second time that the chunks perfectly match the active user’s tenant context.
- The Mechanism: If data mismatched with the user’s tenant key is uncovered during object decryption, the system executes a mandatory “Hard Drop” and transmits a threshold violation alert to the SIEM platform.
4.2. Dynamic Isolation Boundaries in Agentic AI
In emerging Agentic AI environments where autonomous agents invoke various tools and APIs sequentially, structural defense layers must be pre-engineered. This involves issuing short-lived session tokens to each agent’s execution runtime, pinning the boundary of isolation directly at the session level to prevent cross-tenant traversal.
5. Enterprise Data Governance and Practical Checklist
Constructing an enterprise AI architecture requires alignment with global compliance frameworks (such as NIST AI RMF, ISO/IEC 42001, and the EU AI Act).
5.1. Audit Trails and Data Lineage
The core compliance mandate in multi-tenant environments is transparently proving that one tenant’s data has zero visibility impact on another. To satisfy this, all ingestion pipeline logs and vector search queries must index the tenant ID in an encrypted format, creating an immutable foundation for post-incident analysis and data lineage tracking.
5.2. The 10 Commandments Checklist for Data Security Engineers
To implement a secure multi-tenant architecture, data security officers should regularly audit the following controls:
- Pipeline Segregation: Are the ingestion and pre-processing pipelines logically or physically separated for each tenant?
- Mandatory Namespaces: Does the vector database design enforce namespace isolation rather than relying purely on shared metadata filtering?
- Cryptographic Separation: Is every data chunk encrypted using a unique, tenant-specific KMS master key (DEK/KEK architecture)?
- No Application-Side Hardcoding: Is the tenant ID injected automatically by a secure middleware layer during query generation, making it tamper-proof?
- Post-Retrieval Verification: Does the system double-check tenant alignment before injecting retrieved chunks into the LLM’s context window?
- Blast Radius Containment: Are document parsing and chunking engine processes executed inside isolated container sandboxes (e.g., gVisor)?
- Least Privilege Enforcement: Are AI agents restricted via short-lived session tokens to prevent lateral movement across tenant APIs?
- Guaranteed Data Deletion: Does the architecture support a true “Hard Delete” of an entire namespace upon tenant offboarding or contract termination?
- Continuous Red Teaming: Are adversarial tools (e.g., PyRIT) used periodically to simulate tenant boundary traversal attacks?
- SIEM Integration: Are all cross-tenant access anomalies routed directly to the enterprise SIEM system with high-priority alerting?
Conclusion: Securing the AI Frontier Through Engineered Resilience
Data protection in multi-tenant environments is not a matter of simple application-level code exceptions; it is a massive governance infrastructure that must be built at the architectural data engineering level. Over my 20-year career, I have seen that post-hoc security patches are invariably dismantled by evolving adversarial tactics.
A thoroughly designed Defense in Depth architecture at the ingestion stage is the only way to safeguard enterprise data and control the non-deterministic risks of generative AI. Building precise boundaries using metadata and namespaces is the definitive path for modern enterprises seeking to accelerate business innovation while remaining compliant with global regulations.
In our next installment of [The AI Shield], we will explore Part 5: Data Engineering & Pre-processing: Deterministic De-identification, analyzing advanced methods to strip away Personally Identifiable Information (PII) while preserving the core analytical value of enterprise data datasets.
Final Engineering Reflection
For a legacy engineer raised on Relational Databases (RDBs), staring at AI training sets or RAG pipelines can trigger an immediate, almost instinctive urge to manually categorize and partition everything. However, trying to classify data after it has already been pooled is an uphill battle. While we strive to segregate data right at the collection stage, doing so for model fine-tuning often risks overfitting and degrades overall model performance.
Fortunately, RAG environments are far more forgiving in this regard, as they isolate data at the retrieval layer rather than the weights layer. To be completely candid, I am still exploring where the optimal operational balance lies for multi-tenancy implementation across massive scale systems. I look forward to sharing more concrete insights once I have fully implemented this architecture firsthand.