Over my 20-year career designing security infrastructure and operating large-scale data governance frameworks for various organizations, I have witnessed a profound disconnect between architectural ideals and operational realities. If I had to pick the single topic where this gap is widest, it is undoubtedly Data Lineage. While countless enterprise solutions and consulting whitepapers champion the ideal of a comprehensive, top-down map that charts every data flow across the organization, the cold reality is that I have rarely seen a global enterprise successfully maintain an all-encompassing data lineage system in production.
The reality on the ground is far less orderly. Critical data is continuously duplicated across systems to satisfy immediate software requirements or engineering convenience, and these fragmented replicas are then broadcast indiscriminately across the enterprise via ad-hoc interfaces. The same question continually arises: “Why do we continue to replicate and scatter such vital governance assets without strict controls?” This reality forced me to accept a difficult truth: constructing a massive, top-down global data lineage map is structurally unsustainable.
Consequently, the pragmatic and definitive architectural solution I propose is a Bottom-up Micro-Lineage Integration Strategy. We must abandon the fantasy of mapping every single data flow across the entire enterprise simultaneously. Instead, the strategy focuses on building flawless, granular lineages for specific critical data assets that are paramount to governance and security, and then organically linking those micro-maps over time.
In 2026, with Artificial Intelligence (AI) and Retrieval-Augmented Generation (RAG) serving as core enterprise pipelines, this bottom-up approach is more vital than ever. In this sixth installment of [The AI Shield] series, we will dissect the architecture of Critical Asset-Centric Data Lineage Tracking to ensure data trustworthiness and complete security audit trails amid rampant data fragmentation. I will also share a painful practical lesson from our previous entry on deterministic de-identification—specifically, what happens when you omit identifier design during early staging—and outline the design principles required to overcome it.
Series: [The AI Shield] Advanced AI Security and Data Governance Architecture
- System Configuration and Filtering
- Data Engineering and Preprocessing
- Multi-tenancy
- Deterministic De-identification
- Data Lineage Trace (Here!)
- Mathematical Optimization and Advanced Defense
Table of Contents
1. The Paradigm Shift of Data Lineage Tracking in AI Data Engineering
In traditional Business Intelligence (BI) environments, data lineage focused primarily on parsing SQL queries within relational databases (RDBs) to track table- and column-level movements. However, within generative AI and RAG architectures, the format and dimensionality of the data we must track undergo a radical transformation.
1.1 The Chasm Between Structured ETL and Unstructured AI Data Pipelines
Traditional Extract, Transform, Load (ETL) processes operate on fixed schemas, making data mutations relatively straightforward to log and audit. In contrast, AI pipelines ingest highly variable, unstructured data sources such as PDFs, emails, and raw customer interaction logs.
Once these source materials are segmented by a pre-processing engine (chunking) and converted into high-dimensional dense vectors via an embedding model, human readability is entirely lost. From a security engineering standpoint, staring at a raw vector array yields zero context regarding its source document or page origin. This creates an immediate need for a dedicated lineage architecture that explicitly preserves the connection to the raw data source across every semantic transformation phase.
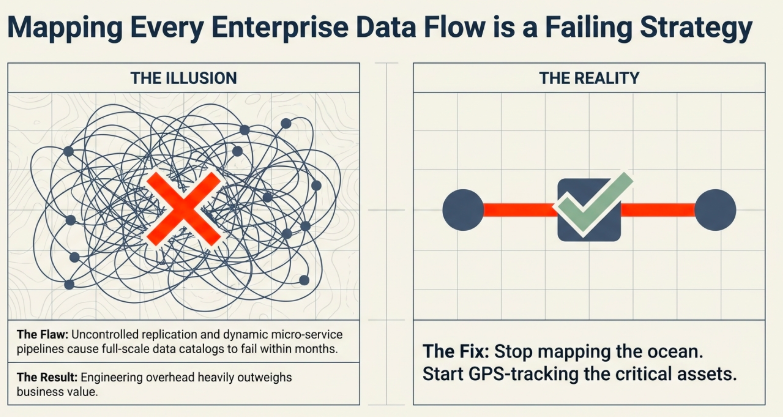
1.2 Anatomy of the Failure of Global Top-Down Lineage
Organizations routinely purchase enterprise data catalog tools and launch sweeping lineage initiatives, only to see them decay into shelfware within a year. The failure modes are highly predictable:
- Unchecked Replication Mechanisms: Data is constantly duplicated across development, staging, analytical, and production environments to fulfill localized engineering needs.
- Limitations of Static Catchment: Real-time streaming data and transient, ephemeral microservice data exchanges slip past static cataloging tools completely.
- Operational Overhead: The engineering hours required to manually document and maintain a flawless global map eventually cross a threshold where the cost far outweighs the business value.
As a result, modern data engineering has shifted to a bottom-up approach, limiting lineage tracking to the core data assets that directly impact security classification and regulatory compliance.
2. Lineage Disconnection Threats in RAG and Generative AI Workflows
While RAG provides a robust framework for anchoring LLM responses in verifiable facts, it introduces major structural break points where data lineage can completely fracture.
2.1 Lost Traceability in the Chunking and Embedding Layers (The Ingestion Gap)
When a source file is uploaded, the pre-processing engine breaks it down into arbitrary blocks of 500 or 1,000 tokens. If the source metadata (author, distribution restrictions, clearance levels) fails to inherit down to the chunk level during this parsing phase, individual chunks become orphaned.
When these blocks are committed to a vector space as mathematical coordinates, auditing a chunk’s lineage after retrieval becomes impossible. If a compromised or corrupted chunk is pulled into the prompt context, security teams have no way to verify its origin or assess data leakage classifications after the fact.
2.2 The Downstream Traceability Challenge of De-identified Tokens
In Part 5, we explored using deterministic de-identification to replace PII with cryptographic tokens or Format-Preserving Encryption (FPE) strings to preserve user privacy.
A common architectural error here is focusing entirely on securing the replacement token while failing to design an explicit relation key (Identity Key) between the raw ancestral data and the de-identified token scale during early pre-processing. If this identifier system is missing, any anonymized data flagged by a SIEM system as an anomaly or security breach cannot be backtracked to its source file in the machine learning training set. This oversight creates massive bottlenecks during 가명정보 (pseudonymized data) combination and lineage reconstruction, often forcing organizations to overhaul their entire data pipeline.
3. Micro-Lineage Design via Open-Source Standards and Lakehouse Frameworks
Implementing an asset-centric micro-lineage requires combining open-source telemetry protocols with the advanced versioning capabilities of modern data lakehouses.
3.1 Integrating the OpenLineage Standard with Pipeline Telemetry
To prevent data lineage fragmentation, architectures should implement the OpenLineage specification. OpenLineage defines pipeline executions through explicit entities: Jobs and Datasets. It captures state changes and input/output metadata using a standardized JSON schema.
- Implementation Strategy: Embed OpenLineage listeners as plug-ins within data orchestration engines like Apache Airflow, dbt, or Apache Spark. As transformation tasks execute, the pipeline emits real-time transformation metrics to a centralized lineage collection engine.
3.2 Anchoring Data States via Apache Iceberg Time Travel
A common issue when tracing critical assets is that source data can be modified or overwritten mid-transit. To ensure reproducibility, deploy Apache Iceberg at the storage layer to enable metadata-level version control.
- The Mechanism: Apache Iceberg utilizes a snapshot-based architecture. By recording the exact source table snapshot ID (
snapshot_id) alongside the derived chunk’s lineage metadata, engineers can execute time-travel queries months later. This allows them to reconstruct and audit the exact historical state of the raw data used during LLM training or RAG retrieval, even if the live table has since been updated or deleted.
3.3 Hardcoded Lineage Metadata Schemas in Vector Databases
When upserting embedding vectors into a vector database (e.g., Milvus, Qdrant), engineers must enforce a standardized lineage schema within the metadata payload:
JSON
{
"tenant_id": "tenant_corp_alpha",
"lineage_metadata": {
"source_document_id": "doc_hr_2025_009",
"ingestion_pipeline_id": "pipe_rag_v2.4",
"chunk_index": 42,
"source_snapshot_timestamp": "2026-05-17T06:15:00Z",
"deterministic_vault_key_ref": "vlt_ref_bc892z"
}
}
Enforcing this payload design ensures that every retrieved embedding chunk carries its own micro-lineage context. Downstream applications and compliance engines can instantly verify the data’s provenance without needing to query a massive, external lineage database.
4. Asset-Centric Scoping and Graph Integration Architecture
To establish a functional bottom-up micro-lineage pipeline, apply the following structural strategy:
4.1 Critical Data Asset Identification and Tagging
Rather than attempting to profile every database table, isolate your high-value targets—such as master customer tables containing PII, proprietary project design files, or finalized financial metrics. Tag these assets explicitly with Critical-Data-Asset: True. This tag acts as a trigger, activating lineage tracing guardrails only when these specific assets enter a data pipeline.
4.2 Context Propagation via API Gateways and Middleware
When data is transferred across microservices or APIs, use the W3C Trace Context protocol to prevent lineage gaps.
- HTTP Header Utilization: Inject an
X-Lineage-Contextheader during API calls to pass the source ID and active Job ID down to the receiving component. This header acts as an unbroken digital thread, tracking the data’s journey until it is safely committed to target storage.
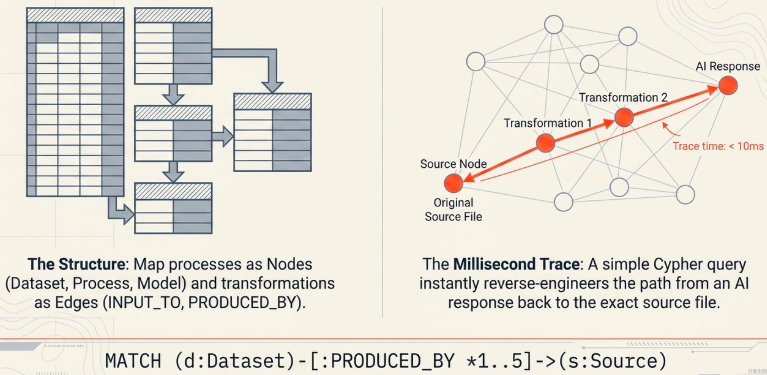
4.3 Unified Lineage Mapping via Graph Databases
Instead of attempting to force micro-lineage JSON events into a monolithic global map, ingest them into a flexible Graph Database (such as Neo4j) as nodes and edges.
| Graph Component | Model Object | Attributes & Metadata Examples |
| Node | Dataset, Process, Model | Database table name, Chunking pipeline ID, LLM version |
| Edge | INPUT_TO, PRODUCED_BY | Processing timestamp, Embedding model algorithm, Tenant permissions |
This graph-based design eliminates the need to map the entire enterprise data footprint. Security teams can trace data lineage instantly by running a localized graph query centered on a critical asset node (e.g., MATCH (d:Dataset)-[:PRODUCED_BY *1..5]->(s:Source)), delivering lightning-fast backtracking performance in production environments.
5. Aligning with Global Regulatory and Enterprise Audit Frameworks
Data lineage tracking is more than an engineering best practice; it is a critical technical defense line required to pass increasingly stringent AI compliance audits.

5.1 Meeting Technical Documentation Mandates under the EU AI Act
The regulatory landscape of 2026 is anchored by the EU AI Act, which imposes rigorous data governance demands on high-risk AI deployments. The law requires complete transparency throughout the data ingestion cycle, meaning that if an AI model produces an erroneous or biased output, the organization must be able to produce the exact lineage of the training data and reference materials that informed that decision.
Similarly, ISO/IEC 42001:2023 mandates strict logging to verify data integrity. An asset-centric graph lineage architecture fulfills these requirements, providing compliance officers with a clear, auditable trail for regulatory reviews.
5.2 Defending Anonymized Pipelines Against Re-Identification Risks
When reusing pseudonymized or 가명정보 (garbled/anonymized) datasets, compliance engines must verify that the data traveled through an approved, legally compliant de-identification pipeline.
A graph-based micro-lineage demonstrates this compliance without exposing raw identifiers. It proves programmatically that a given token (e.g., Token_A9x8) was generated using a verified KMS_Key_V1 via an authorized pre-processing path, protecting the organization from post-incident regulatory liability.
6. The 10-Point Data Lineage Checklist for Security Engineers
To successfully implement a bottom-up micro-lineage tracking framework, evaluate your architecture against these ten operational requirements:
- Critical Asset Scoping: Have you bypassed the global map trap to focus exclusively on highly classified and regulation-critical data assets?
- OpenLineage Activation: Are OpenLineage listeners natively integrated into your core ingestion orchestrators (e.g., Airflow, dbt)?
- Chunk-Level Inheritance: Do document parsers explicitly map a parent file’s ID and security attributes onto every child chunk?
- Cryptographic Lineage Anchoring: Does your deterministic de-identification pipeline include an identity relation key to link safe tokens back to their raw source lineages?
- Vector DB Payload Compilation: Is your vector database schema configured to mandate lineage metadata fields within every upserted payload?
- Snapshot Storage Integration: Are storage platforms using frameworks like Apache Iceberg to enable time-travel queries against historical source data states?
- Header Propagation Verification: Do your API gateways pass lineage context headers down through microservice hops without dropping payloads?
- Graph Database Mapping: Are micro-lineage events routed into a graph database (e.g., Neo4j) to allow fast, localized node backtracking?
- Audit Log Immutability: Are collected lineage logs committed to tamper-proof, write-once-read-many (WORM) storage environments?
- Compliance Validation: Does your micro-lineage map satisfy the exact data traceability criteria required by the EU AI Act and ISO 42001?
Conclusion: Achieving AI Transparency Through Strategic Scoping
Attempting to map an all-inclusive enterprise data lineage is a surefire way to burn out engineering teams in modern environments marked by rampant data replication. True data security and governance do not require total surveillance of every harmless byte; they demand absolute precision over the data assets that matter most.
By focusing on a critical asset-centric micro-lineage, organizations can draw clear defensive boundaries around their high-value data. When built directly into the pre-processing layer, this lineage framework strips away the “black box” stigma of generative AI, transforming your systems into transparent, audit-ready, and highly trusted business assets.
In our next installment of [The AI Shield] series, we will move to Part 7: Embedding Noise Injection, the first entry in our Mathematical Optimization and Advanced Defense phase. We will explore how injecting calculated mathematical noise into high-dimensional vector spaces can block external similarity extraction attacks without degrading retrieval quality, taking a look at a highly sophisticated defense layer.
Tags:
#DataLineage #DataEngineering #AISecurity #TheAIShield #RAGGovernance #OpenLineage #ApacheIceberg #GraphDatabase #EU_AI_Act #NIST_AIRMF #DataGovernance #EnterpriseArchitecture
Recommended Titles:
- Data Lineage Tracking: Essential Enterprise Architecture and Implementation Strategy
- Building an Asset-Centric Micro-Lineage Framework for Secure RAG Pipelines
- A Bottom-Up Approach to Data Lineage Tracking in Enterprise AI Systems
Final Engineering Reflection
In past projects, we attempted to map lineage using non-intrusive data tracking—essentially parsing application logs and database execution plans to avoid altering the raw data itself. Because we left the underlying data untouched, replication continued unabated, and developers found increasingly creative, unmonitored ways to copy datasets. Every attempt to build a global map using that method failed. However, modifying data in a live production environment to enforce tracking can severely impact business operations. This is why a targeted, small-scale approach focusing exclusively on critical data assets is the most viable path forward. We will begin by mapping our highest-value assets first, and I will share our progress as the architecture evolves.