When I first encountered the concept of embedding noise injection, my immediate reaction was, “How exactly do you inject noise into a prompt?” I wondered if it was analogous to introducing noise into images to optimize license plate recognition. However, as I dove into the study and the discourse shifted toward vector spaces and high-dimensionality, it brought back vivid memories of my university days.
Graduating with a degree in mathematics yields practical benefits after all. Let us begin. Since I lack direct hands-on implementation experience with embedding noise injection, I will focus on structural frameworks and underlying mathematical methodologies.
Reflecting on this topic reminds me of the economic anxieties I faced right after graduation when options seemed limited to private academy tutoring. Studying this framework now makes me realize how a deeper grasp of advanced mathematics opens doors to completely different career domains; regardless, that university foundation certainly accelerated my conceptual understanding of high-dimensional vector security.
As Artificial Intelligence (AI) matures into a foundational enterprise infrastructure, organizations are rapidly deploying Retrieval-Augmented Generation (RAG) pipelines. Vast volumes of confidential documents, proprietary technical assets, and sensitive customer interaction logs are continuously ingested through embedding models and committed to Vector Databases (Vector DBs). However, data engineers and security architects frequently overlook a critical vulnerability hidden deep within these high-dimensional numerical spaces: Embedding Inversion Attacks and Similarity Extraction Attacks.
A prevalent misconception holds that because text loses human readability the moment it transforms into a high-dimensional dense numerical array, it is inherently safe from unauthorized reconstruction. This is a mathematical illusion. By exploiting consistent proximity-measurement algorithms and reverse-engineering the minute coordinate shifts of floating-point values, adversaries can systematically reconstruct raw source documents textually, down to individual tokens and characters. This threat completely exposes static data storage layers.
The definitive enterprise solution to mitigate data exfiltration within high-dimensional vector spaces is Embedding Noise Injection. In this seventh installment of the [The AI Shield] series, we provide a rigorous analysis of an embedding protection architecture anchored in Differential Privacy. This methodology introduces calculated random perturbations directly into high-dimensional mathematical vector structures while leaving text prompt utility fully intact. We examine the mathematical optimization strategies required to successfully balance robust security with semantic search precision at the intersection of the curse and blessing of dimensionality.

Series: [The AI Shield] Advanced AI Security and Data Governance Architecture
- System Configuration and Filtering
- Data Engineering and Preprocessing
- Mathematical Optimization and Advanced Defense
- Embedding Noise Injection (Here!)
- Logical Partitioning
- Embedding Model Bias Verification
- Honey-token Injection
Table of Contents
1. Mechanics and Threat Scenarios of Inversion Attacks on Vector Databases
Traditional system breaches typically target raw text records or structured database rows. In contrast, intellectual property exfiltration within generative AI ecosystems targets seemingly secure vector APIs and embedding coordinates directly.
1.1 Deep Dive into Embedding Inversion Attacks
An adversary systematically executes tens of thousands of meticulously structured queries against a target RAG system, harvesting the returned retrieval weights and semantic similarity scores. Because an embedding model is an algebraic function with static weights, inputs that share conceptual meaning inevitably converge near specific multi-dimensional coordinates. Using these harvested data points, adversaries train a supervised machine learning decoder model designed specifically to map dense numerical arrays back into coherent text strings. This reverse-transformation model decodes floating-point patterns within the dense vectors to reconstruct critical keywords, source code, system credentials, and financial metrics with devastating precision.
1.2 High-Dimensional Numerical Layer Attacks vs. Prompt Pollution
While security teams heavily emphasize text-layer defenses such as prompt injection filtering or jailbreak detection, embedding inversion attacks operate natively within the deepest geometric computation layer of the AI pipeline. Web Application Firewalls (WAFs) and standard text filters cannot intercept or analyze these matrix-based proximity calculations. Consequently, organizations must implement an architectural guardrail that introduces structured perturbations to the mathematical outputs without disrupting the downstream availability of the source data.
2. Geometric Principles of Embedding Noise Injection and Differential Privacy
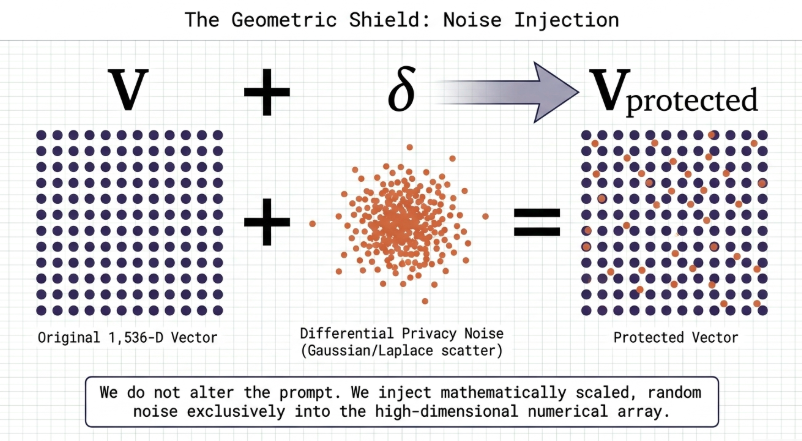
Embedding noise injection does not alter or corrupt the characters of the initial user prompt. The input text processes through the embedding model natively, and calculated stochastic noise is introduced exclusively at the resulting high-dimensional dense numerical array phase.
2.1 Runtime Vector Perturbation via Algebraic Customization
The moment a user query or a reference document converts into an original vector $V$ within a 1,536-dimensional space, the internal defense middleware injects a Gaussian or Laplace noise vector $\delta$ calibrated to Differential Privacy specifications:
$$V_{\text{protected}} = V + \delta$$
The perturbation vector $\delta$ is not a purely arbitrary random sequence. It is an explicitly scaled vector calculated based on the dimensional density of the specific embedding model and the system’s threshold for acceptable error margins.
2.2 Neutralizing Adversarial Recovery via Deterministic Perturbation
The addition of the micro-noise $\delta$ shifts the target coordinates slightly from their original positions within the vector space. Adversarial recovery algorithms that rely on evaluating fine floating-point variations down to the fourth or fifth decimal place face compounding computational errors due to these variations. As a result, the semantic decoder produces entirely fragmented, incoherent output, completely neutralizing the reverse-engineering attempt.
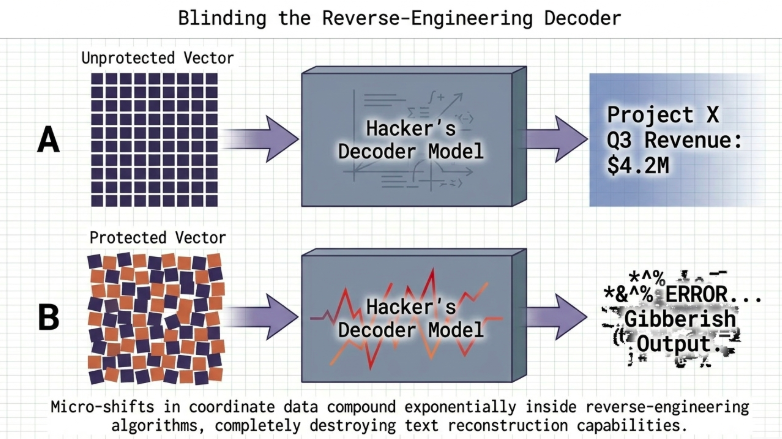
3. The Geometry of High Dimensions: Preserving Search Performance Amid Perturbation
The question of how a RAG system maintains search accuracy when its underlying coordinates are intentionally altered is answered by two core principles of high-dimensional geometry: the blessing of dimensionality and relative rank preservation.
3.1 The Blessing of Dimensionality and Spatial Margin
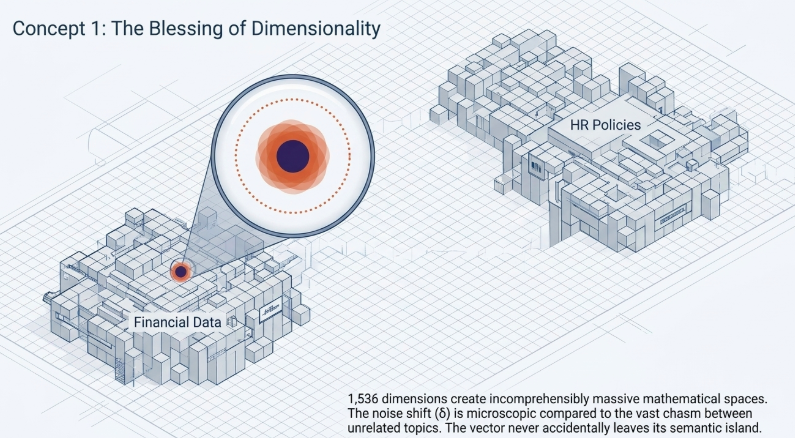
In standard two-dimensional or three-dimensional spaces, shifting a coordinate even slightly easily pushes it into an adjacent data territory, corrupting its meaning. However, the 1,536 or 3,072-dimensional spaces utilized by production-grade Large Language Model (LLM) embedding engines are exceptionally vast. Within these expansive high-dimensional environments, semantically related data points cluster tightly together into massive, isolated semantic islands (clusters) separated by immense vacant voids. Because these empty boundaries are so wide, introducing a micro-noise vector $\delta$ moves the coordinate locally but keeps it well within the perimeter of its original semantic cluster, preventing unintended overlap with unrelated data domains.
3.2 Absolute Coordinate Shifts vs. Relative Proximity Ranking
RAG retrieval engines do not depend on absolute coordinate addresses. Instead, they calculate relative rankings—such as Cosine Similarity or Euclidean Distance—to return the top $k$ closest documents relative to a query. For instance, if an ideal matching document $A$ sits at a mathematical distance of 10 from a query, and an unrelated document $B$ sits at a distance of 80, introducing noise might shift document $A$ to a distance of 10.15 and document $B$ to 79.85. The absolute values change, but the relative order remains completely unaffected. The system continues to retrieve the correct document $A$ flawlessly, ensuring that the end-user observes zero degradation in answer precision.
4. Dimensional Scaling and Noise Threshold Design for Production LLMs
Deploying a resilient noise-injection architecture requires an exact calibration of the hyper-parameters to match the dimensional scale of the chosen enterprise embedding engine.
4.1 Architectural Dimensions Across Enterprise and Open-Source Models
Production embedding architectures optimize dimensions to balance semantic fidelity with computing overhead across distinct operational tiers:
| Model Class | Representative Embedding Suite | Dimensions | Primary Enterprise Use Cases |
| High-Performance | OpenAI text-embedding-3-large | 3,072 | High-precision legal/financial compliance audits |
| Industry Standard | OpenAI text-embedding-3-small / ada-002 | 1,536 | General enterprise RAG pipelines, corporate chatbots |
| Efficiency-Focused | Google Vertex AI text-embedding-005 | 1,024 | Real-time mass streaming data indexing and discovery |
| On-Device / Light | HuggingFace bge-small / Microsoft E5 | 384 to 768 | Local mobile search, memory-constrained edge nodes |
4.2 Matryoshka Embedding Adaptations for Dynamic Security Guardrails
The introduction of Matryoshka Representation Learning in modern embedding models allows for highly flexible security configurations. Matryoshka models allow engineering teams to truncate a 3,072-dimensional vector down to 1,024 or 512 dimensions without discarding the core semantic information. This enables a Dynamic Tiered Security Framework: non-sensitive, public-facing documentation can be compressed to lower dimensions to optimize computation speeds and minimize storage costs, while highly classified, core intellectual property assets retain their full 3,072-dimensional structure and receive robust Differential Privacy noise injection to maximize defensive resilience.
5. Scaling Mass Calculations with High-Speed Vector Database Indexing
As dataset dimensions expand, calculating absolute distance pairs across millions of vectors introduces severe computing bottlenecks that can cause production latency to spike.
5.1 Seamless Integration with Hierarchical Navigable Small World (HNSW) Indexes
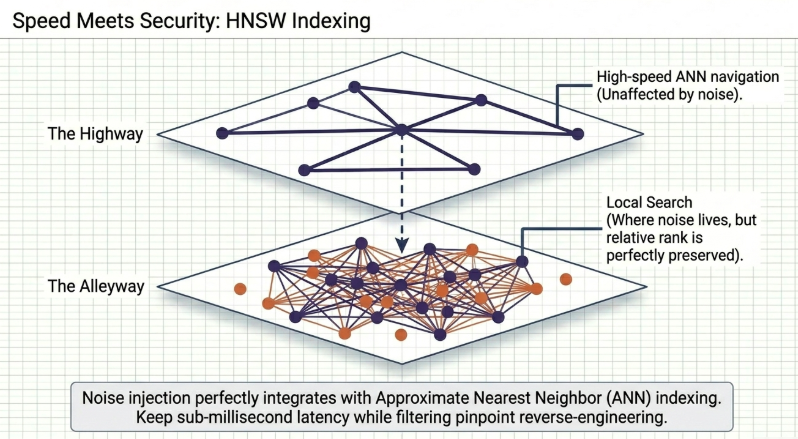
To bypass this bottleneck, enterprise vector databases deploy HNSW graphs to enable approximate nearest neighbor (ANN) discovery. HNSW structures data across multi-layered routing networks: an upper express layer performs broad data jumps to locate general regions, while dense lower layers conduct localized calculations to pinpoint exact matches.
Embedding noise injection integrates natively with this multi-layer architecture. The micro-noise added to a query vector does not disrupt its macro-routing path across the upper express layers of the graph. The query successfully reaches the correct target data cluster, and localized rank preservation takes over at the final dense layer. This allows organizations to enjoy high-speed retrieval—processing queries across hundreds of millions of records in mere milliseconds—while maintaining a highly effective shield against reverse-engineering attacks.
6. The 10-Point Technical Checklist for Security Engineers
To successfully transition an enterprise RAG architecture to a noise-protected high-dimensional infrastructure, security engineers should validate their implementation against the following ten architectural mandates:
- Attack Surface Mapping: Have you audited all public vector API boundaries and vector database access controls to isolate pipelines vulnerable to similarity extraction?
- Optimal Bound Calculation ($\epsilon$): Have you run empirical tests to identify the precise Differential Privacy noise boundaries that maximize adversarial confusion without degrading RAG hit rates?
- Gaussian Noise Scaling: Is the variance of your perturbation vector $\delta$ dynamically scaled to diminish in proportion to the square root of the model’s total dimensionality?
- Matryoshka Strategy Alignment: Have you enforced lower-dimensional truncation for public data tiers while maintaining maximum dimensionality and noise injection for core data assets?
- HNSW Graph Tuning: Have you recalibrated the vector database’s
efSearchandMhyper-parameters under noise conditions to prevent recall drops? - Text Layer Independence: Is the noise calculation isolated entirely to memory-resident numerical arrays, ensuring raw user prompt text remains untouched?
- Salt Seed Rotation: Are the cryptographic seeds driving your Pseudo-Random Number Generators (PRNG) rotated automatically to prevent adversaries from modeling the noise patterns?
- Extraction Rate Limiting: Are strict throttling and API rate limits enforced on embedding extraction endpoints to prevent adversaries from averaging out noise through high-volume iterative querying?
- Hybrid Re-ranking Integration: Is the pipeline integrated with a Part 3 hybrid re-ranking layer to validate the keyword-level (BM25) alignment of noise-retrieved documents?
- Latency Telemetry: Are monitoring tools tracking end-to-end inference latency to ensure noise injection tasks fit within production budgets (e.g., < 50ms)?
Conclusion: Mathematical Guardrails Enforcing Complete Data Privacy
Traditional data governance establishes security by blocking entry pathways, segregating access roles, and masking explicit identifiers. Embedding noise injection introduces an entirely different defensive paradigm: it implements a mathematical guardrail natively within the high-dimensional geometric space to render stolen data useless to adversaries.
By turning the curse of dimensionality into a defensive asset, this architecture preserves the speed and analytical depth of enterprise RAG pipelines while stripping adversaries of the ability to reverse-engineer core intellectual property. When organizations keep user text pristine but mask underlying numerical coordinates, generative AI systems shed the liabilities of a black box and transform into highly secure, audit-ready corporate assets.
In our next entry of [The AI Shield] series, we will examine Part 8: Logical Partitioning. We will explore methodologies to construct robust logical barriers across tenants and security classifications within a unified vector cluster, enabling secure dynamic routing without the infrastructure overhead of physical hardware isolation.
Final Engineering Reflection
Studying embedding noise injection reminds me of when I worried about making a living after graduating with a math degree. Back then, the only job available to a math graduate was being a private academy instructor. Now, as I study embedding noise injection like this, I find myself wondering if I could have pursued a different career had I been better at math. Well, I suppose the fact that I learned a little bit in college is helping me understand embedding noise injection a bit faster.