Working Title: Hybrid Re-ranking – The Essential Gateway to AI Trustworthiness and Data Protection.
The integration of artificial intelligence architectures introduces a fundamental paradigm shift in enterprise infrastructure protection, transforming deterministic security operations into adaptive behavioral governance. Traditional security models operate on deterministic parameters, enforcing access isolation through static boundaries and fixed authentication gates. Conversely, contemporary AI-driven runtime environments require the management of probabilistic, highly non-deterministic model behaviors.
Adapting existing security engineering frameworks to this topology necessitates integrating hybrid search and retrieval-validation layers to govern context ingestion boundaries.
The implementation of Hybrid Re-ranking functions as a structured security control within this shifting paradigm. While the mathematical formulations of concurrent vector and keyword retrieval are well-defined, the security utility of re-ranking operates directly on the context window payload of Retrieval-Augmented Generation (RAG) environments.
By executing a secondary validation and alignment phase on unstructured data inputs, this mechanism programmatically suppresses model hallucinations and enforces data protection boundaries. This section analyzes the underlying architecture, algebraic combination mechanics, and practical engineering implementations required to deploy Hybrid Re-ranking as a core security control within enterprise RAG pipelines.

Series: [The AI Shield] Advanced AI Security and Data Governance Architecture
- System Configuration and Filtering
- Prompt Injection Defense Design
- Metadata Filtering
- Hybrid Reranking (Here!)
- Data Engineering and Preprocessing
- Mathematical Optimization and Advanced Defense
Table of Contents
Introduction: The Gatekeeper of AI Trustworthiness and the Necessity of Hybrid Search
In 2026, generative AI has transitioned from an experimental asset into core economic infrastructure reshaping enterprise decision-making. By pairing Large Language Models (LLMs) with massive internal corporate knowledge bases via RAG, organizations have seen exponential productivity gains—personally, I observe a 5x to 10x acceleration in knowledge discovery workflows. Yet, this rapid data synthesis introduces unprecedented risks regarding data sovereignty and system reliability.
To build a truly trustworthy AI system, security architecture cannot be treated as an afterthought; it must be an foundational principle baked directly into the design phase. Within a RAG workflow, retrieval quality acts as the primary gatekeeper of the entire system’s reliability. Relying solely on vector search introduces subtle vectors for misinformation and compliance failure. Hybrid Re-ranking bridges this gap by securing lexical precision and semantic context simultaneously.
1. Technical Mechanisms and Working Principles of Hybrid Re-ranking
Hybrid Re-ranking optimizes retrieval quality by combining the distinct strengths of traditional keyword-based matching and deep learning-based vector search. This combination is highly effective at reducing the probability of an LLM fabricating an ungrounded response, directly strengthening the model’s faithfulness.
1.1. BM25: Lexical Precision and Exact Token Matching
BM25 (Best Match 25) is a highly reliable probabilistic algorithm that scores documents based on term frequency ($f$) and inverse document frequency ($\text{IDF}$). It remains unmatched when a query requires pinpoint accuracy for specific tokens, such as part serial numbers, proper nouns, unique product IDs, or precise legal terms.
The mathematical core of BM25 is formulated as follows:
$$\text{Score}(D, Q) = \sum_{q \in Q} \text{IDF}(q) \cdot \frac{f(q, D) \cdot (k_1 + 1)}{f(q, D) + k_1 \cdot (1 – b + b \cdot \frac{|D|}{\text{avgdl}})}$$
In this equation, $k_1$ regulates the term frequency saturation nonlinear limit, while $b$ dictates document length normalization, ensuring that longer documents do not artificially dominate search scores.
1.2. Vector Search: Dense Semantic Mapping and Intent Discovery
Vector search converts text chunks into high-dimensional dense embeddings to measure contextual similarity. This allows the system to identify highly relevant documents even if the user uses completely different vocabulary or synonyms to express their intent. Typically computed via Cosine Similarity, it evaluates the geometric angle between the query vector and document vectors to establish conceptual relevance.
2. Reciprocal Rank Fusion (RRF) and the Two-Stage Re-ranking Process
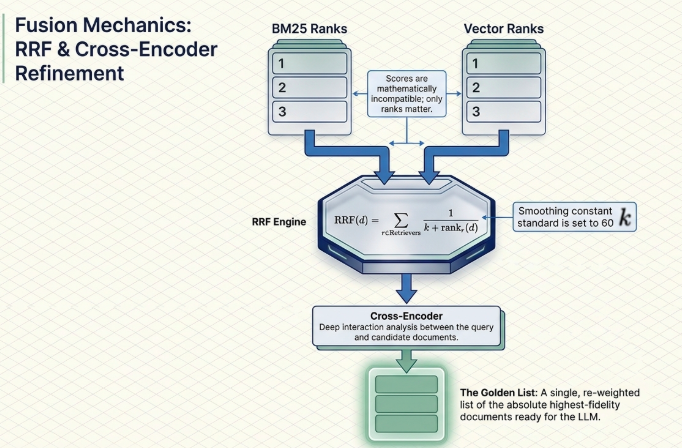
The true engineering challenge of hybrid retrieval lies in unifying these two entirely distinct scoring systems (BM25’s open-ended scale and Vector Search’s bounded similarity score) into a single, cohesive result list.
2.1. The Mathematical Integration of Reciprocal Rank Fusion (RRF)
RRF bypasses the issue of incompatible raw score distributions by evaluating only the relative rank of a document within each respective retrieval method.
The RRF score for a document $d$ is calculated using the following formula:
$$\text{RRF}(d) = \sum_{r \in \text{Retrievers}} \frac{1}{k + \text{rank}_r(d)}$$
Where $k$ is a constant multiplier (typically optimized around 60) that dampens the influence of low-ranking outliers.
2.2. Cross-Encoder Based Precision Re-ranking
While RRF creates a solid unified baseline, advanced architectures pass the top candidates to a deep-learning-based Cross-Encoder for a definitive evaluation.
- Stage 1 (Bi-encoder): Uses traditional embeddings and BM25 to independently scan millions of documents, surfacing a broad candidate pool (e.g., top 100 results) with minimal latency.
- Stage 2 (Cross-encoder): Feeds the query and each candidate document simultaneously into a highly specialized transformer layer. This layer performs an exhaustive cross-attention check to analyze deep token-to-token interactions, outputting a precise relevance score to determine the final ordering.
3. Authorization-Aware Retrieval Design from a Security Architecture Perspective
As a security practitioner, the absolute rule I enforce in any enterprise deployment is simple: “If a user does not have explicit permission to view a piece of data, it must be mathematically impossible for the system to retrieve it.”
3.1. Pre-filtering and Database Row-Level Security (RLS)
Modern secure RAG architectures reject post-retrieval filtering in favor of Authorization-aware Pre-filtering.
- Metadata Ingestion: During the data pipeline ingestion phase, immutable access control tags (such as
tenant_id,department_clearance, orallowed_roles) are appended directly to every distinct data chunk. - Deterministic Query Restriction: When a user submits a query, the application interceptor extracts their verified identity tokens from the IAM (Identity and Access Management) layer and injects these attributes directly as hard constraints into the vector database query.
- Enforcing Database-Level RLS: Forcing Row-Level Security directly at the database engine layer ensures that even if an intermediate LLM generates a flawed or manipulated retrieval query via an injection attack, the underlying data store physically bars access to unauthorized records.
3.2. Preventing Side-Channel Leaks in the Re-ranking Stage
The re-ranking layer must also operate strictly within the user’s verified security boundary. The cross-encoder model must only accept a candidate list that has already passed through the pre-filtering authorization checkpoint. Furthermore, raw re-ranking relevance scores must be guarded to prevent information leak vectors (side-channel analysis), where a malicious actor might infer the existence of a highly confidential document based on subtle variations in systemic latency or scoring shifts. Every step of this execution path feeds into the system’s immutably recorded Audit Trail, validating end-to-end compliance.
4. Enterprise Use Cases: Real-World Implementation and Security Triumphs
Hybrid Re-ranking has moved beyond academic theory; it is now an established standard across top-tier enterprise architectures.
4.1. Stack Overflow and Spotify: Optimizing Discovery
- Stack Overflow: Implemented a hybrid engine combining BM25 exact matching for rare error codes with dense vector models to decipher ambiguous natural language programming queries. This dual approach resolved user intent even when developers lacked the precise technical terminology.
- Spotify: Merged lexical matching of tracks with real-time behavioral signals at the re-ranking tier, driving a 27% increase in user click-through rates (CTR) on heavily conversational or vague search prompts.
4.2. Adobe and Mercedes-Benz: Hardening Enterprise RAG
Adobe and Mercedes-Benz deployed Hybrid RAG architectures to handle highly sensitive technical manuals and legal contracts. By enforcing exact lexical matches on stringent part numbers and combining them with semantic intent verification, they reduced model hallucination rates by over 50%. This ensured that their customer support AI agents generated text grounded strictly in verified corporate engineering data.
5. Balancing Performance with Cost: Operational KPI Management
A resilient security design must also be operationally viable. Introducing cross-encoders and multi-stage retrieval can add computational overhead. Managing the following Core KPIs is vital for production deployments:
| Core KPI | Definition & Measurement | Hybrid Search Considerations |
| TTFT (Time to First Token) | Total latency elapsed before the LLM streams its first output token. | Heavily dependent on retrieval and re-ranking execution speeds. |
| Recall@K | The proportion of highly relevant documents captured within the top $K$ results. | Hybrid models consistently outperform pure vector indexes on this metric. |
| nDCG / MRR | Metrics evaluating the precision and positional relevance of top-ranked items. | Requires careful fine-tuning of RRF dampening constants ($k$). |
| Infrastructure Costs | RAM overhead for dense vector indexing and GPU compute requirements for cross-encoders. | Requires optimization of chunk allocation and resource provisioning. |
To effectively balance latency and infrastructure spend, production environments often implement Semantic Caching. High-frequency queries are evaluated against a cache of previously authorized results, drastically cutting down on redundant GPU cycles and lowering average response times.
6. Regulatory Alignment and Compliance Mapping
Constructing an enterprise AI architecture requires alignment with emerging global compliance frameworks:
- NIST AI RMF 1.0: Focuses heavily on managing systemic risk across the entire AI lifecycle. Hybrid re-ranking serves as a technical control directly fulfilling the ‘Govern’ and ‘Mitigate’ criteria by ensuring data traceability.
- ISO/IEC 42001:2023: Establishes a verifiable Artificial Intelligence Management System (AIMS). It demands structured operational controls, making multi-stage retrieval audits a core component of continuous risk evaluation.
- EU AI Act: Enforces strict compliance mandates on high-risk AI deployments, legally requiring data provenance, technical documentation, and rigorous logging.
By utilizing a hybrid re-ranking pipeline, the system generates precise grounding logs for every extracted source document. This provides the concrete audit trail necessary to satisfy independent compliance reviews.
Conclusion: Securing the AI Frontier Through Engineered Resilience
Building a trustworthy AI system is not about adopting a single patch or tool; it is about establishing an engineered architecture where governance and technical controls operate in harmony. From my perspective as a veteran security engineer, hybrid re-ranking represents a major evolutionary leap forward—it transforms the retrieval process from a loose game of probabilistic guesswork into an auditable, highly precise data gateway.
By anchoring semantic vector models with the concrete precision of lexical matching, and layering it with authorization-aware pre-filtering, an enterprise can confidently unlock the value of its private data. Security is never a static target; it is a continuous process of measuring, auditing, and hardening.
In our next installment of [The AI Shield], we will shift our focus to Part 4: Data Engineering & Pre-processing, where we will explore multi-tenancy isolation and deterministic data de-identification strategies across the broader ingestion lifecycle.
Final Engineering Reflection
For an engineer who grew up on low-level code and hard logic, adopting ranking and scoring systems can feel counterintuitive. In early production environments, ranking algorithms were historically notorious for being unstable and difficult to fit reliably under shifting conditions. However, the maturation of data engineering and modern system rebalancing allows us to construct highly predictable, stable pipelines. Exploring these architectures isn’t just an option anymore—it’s the definitive path forward for building secure enterprise systems.