This section marks the beginning of the implementation phase. For this reason, the comprehensive architecture design is positioned at this stage of the development roadmap. Utilizing LLMs throughout this process functions similarly to expanding team capacity; however, the output of an AI assistant remains bounded by the context, domain knowledge, and constraints provided by the engineer.
Initial assumptions that automation would entirely replace human engineering teams have evolved. The shift in software development underscores that automated code generation does not replace core engineering competencies. Instead, the utility of these tools depends heavily on a developer’s mastery of software engineering fundamentals, deep domain expertise, and practical architectural experience. In an AI-assisted development landscape, technical oversight and a strong foundational background remain essential for effective system design.

- Project Repository: github.com/zafrem/bastion-rag
Series Name: Bastion-RAG – Project Security RAG
- [Bastion-RAG] Project Security RAG
- [Bastion-RAG 0] Get help from AI (Architecture Design) – Here!
- [Bastion-RAG 1 – Sentinel]
- Prompt Injection Defense
- Metadata Filtering
- [Bastion-RAG 2 – Vault]
- Multi-tenancy
- Deterministic De-identification
- [Bastion-RAG 3 – Navigator]
- Hybrid Reranking
- Logical Partitioning
- [Bastion-RAG 4 – Archor]
- Embedding Noise Injection
- Embedding Model Bias Verification
- [Bastion-RAG 5 – Tracker]
- Data Lineage Tracking
- Honey-token Injection
- [Bastion-RAG Demo]
목차
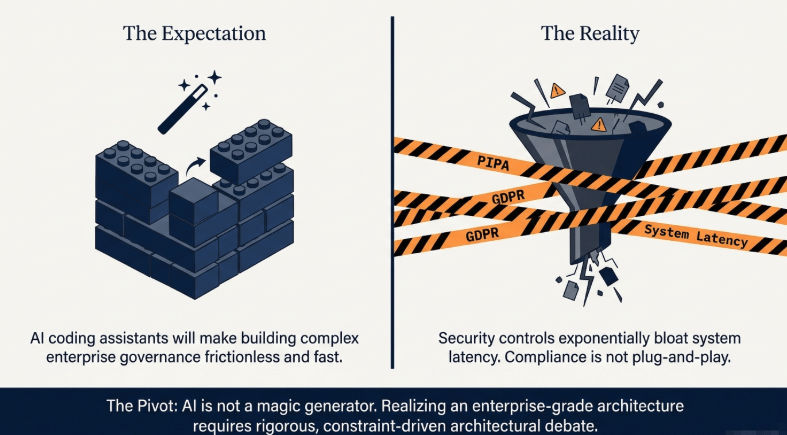
The Bastion-RAG project was initiated to implement security governance layers—including prompt injection defense, deterministic tokenization, and differential noise injection—into a production-ready system. Initial development assumed that integrating these security features would be straightforward given the capabilities of modern AI coding assistants.
While initial code generation was completed quickly, architectural implementation introduced complex design variables. Establishing an architecture that satisfies enterprise compliance mandates (such as PIPA and GDPR) while minimizing runtime latency on live data pipelines posed a significant challenge. Appending security control layers naively increased system latency beyond acceptable metrics. Resolving these performance bottlenecks required three structural iterations of the core framework and extensive design validation with the AI assistant.
This post serves as an engineering retrospective detailing how the pipeline’s structure was refined through automated validation and meticulous execution overhead measurement to construct a secure RAG governance framework.
2. Evolutionary Analysis: The Dramatic Structural Journey from v1 to v3
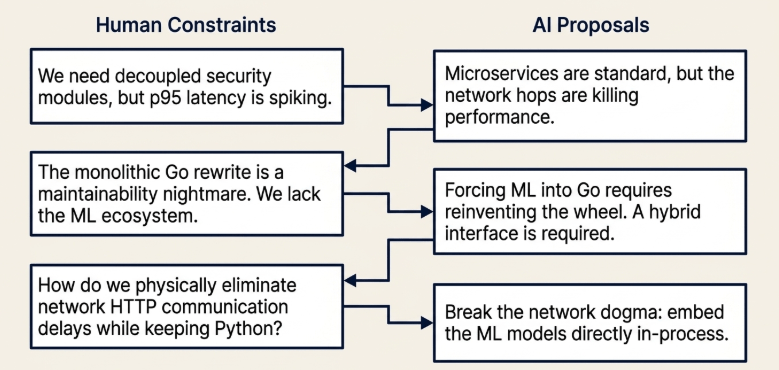
Reviewing the architectural design prompt records exchanged with the AI assistant reveals a continuous cycle of technical friction, rapid prototyping, and a stark realization of my own initial research gaps.
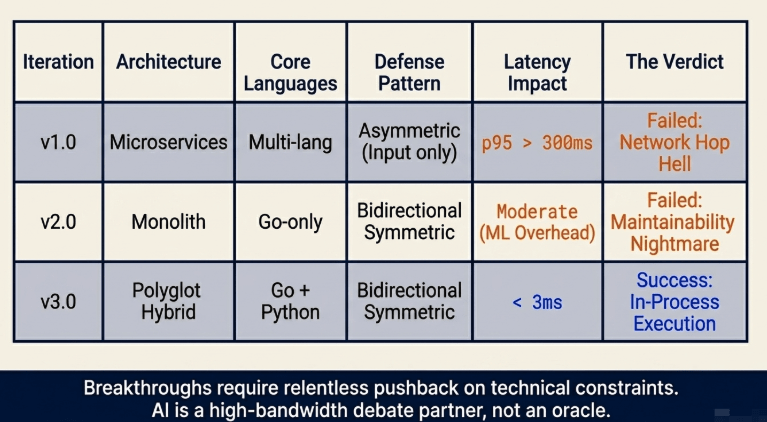
2.1 [Version 1.0] The Swamp of Functional Fragmentation and Asymmetry (Failure)
- Initial Architectural Profile
- The initial iteration implemented a unidirectional defense architecture focused primarily on the input pipeline. Each security component, including
Sentinel-INandVault-IN, operated as a decoupled microservice or independent container. TheHoney-Tokenintrusion detection system was also designed as an isolated function confined within theTrackermodule.
- The initial iteration implemented a unidirectional defense architecture focused primarily on the input pipeline. Each security component, including
- Design Intent and Architecture Selection
- The initial objective was to decouple the security modules to ensure system extensibility. The architecture featured an inbound gateway written in Go, with the embedding generation and reranking components isolated in a separate Python model server accessed via HTTP calls. This approach adopted standard microservice principles to establish clear deployment boundaries across domains.
- Performance and Security Evaluation
- Integration benchmarks revealed significant performance overhead. Each retrieval request triggered multiple external microservice calls, accumulating HTTP network hop delays and serialization/deserialization overhead. As a result, p95 latency increased beyond 300ms, failing to meet real-time processing requirements.
- Additionally, benchmarking exposed a structural asymmetry in the pipeline. The exclusive focus on inbound validation resulted in the omission of an output verification phase. This created a security risk where the LLM could include raw personal data or unauthorized enterprise secrets in its final response, bypassing storage-level isolation mechanisms.
2.2 [Version 2.0] Discovery of Symmetrical Integration and Cross-Cutting Dynamics (Transition)
- Revised Architectural Profile
- The second iteration consolidated the separate input (Phase 1) and output (Phase 2) modules into a bidirectional symmetric architecture within a single Go service container. Features such as
Honey-Tokens,Multi-Tenancy, andData Lineagewere refactored from isolated modules into cross-cutting system-wide coordinators.
- The second iteration consolidated the separate input (Phase 1) and output (Phase 2) modules into a bidirectional symmetric architecture within a single Go service container. Features such as
- Language Ecosystem Limitations
- Consolidating the pipeline into a single Go process eliminated network hop latency, but introduced limitations in the machine learning operation layer. The Go ecosystem lacks native primitives for operations like Word Embedding Association Tests (WEAT) or Laplacian noise distributions, requiring custom low-level implementation. Strict single-language consolidation created a maintenance burden and limited architectural flexibility. The system required a hybrid interface contract capable of maintaining performance isolation while leveraging the Python machine learning ecosystem.
- Limitations of the Transition
- While this single-language consolidation resolved the network latency bottleneck, it introduced maintenance challenges due to machine learning serving overhead and complex CGO bindings.
2.3 [Version 3.0] Completion of the High-Performance Polyglot Wire Contract (Current)
- Final Architectural Profile
- The final iteration retains the symmetrical dual-phase pipeline and decoupled module design established in v2.0, implementing an optimized hybrid polyglot structure. High-speed text pattern matching and cryptographic token mapping are handled by Go, while vector embeddings and matrix numerical operations are managed entirely by Python.
- Inter-Process Communication Optimization
- To leverage the Python machine learning ecosystem without introducing the network communication latency observed in v1.0, the
Navigator(Search) andAnchor(Security) modules were redesigned as self-contained Python processes. Hosting thesentence-transformersandCrossEncodermodels directly within process memory allows inference to be executed in-process, eliminating network hops. - To bridge the multi-language boundary, the system utilizes a gRPC infrastructure. The standard binary protobuf layer is replaced with a custom JSON Codec contract on the wire, balancing structural flexibility with strict type safety.
- To leverage the Python machine learning ecosystem without introducing the network communication latency observed in v1.0, the
3. [Bastion-RAG 0] Virtual Emulation Simulation for Architecture Design
Through three architectural iterations, implementation demonstrated the necessity of validating configuration compliance and exception handling paths prior to codebase development. To integrate this approach into the development lifecycle, Bastion-RAG 0 was established as a proactive architectural auditing layer at the framework’s entry point.
When enterprise security policies and compliance constraints are defined, Bastion-RAG 0 emulates the pipeline’s event stream over a NATS event bus topology. This emulation runs without loading machine learning models or initializing concrete services.
Once a proposed pipeline configuration is provided, the Bastion-RAG 0 audit engine dynamically generates a real-time Virtual Ingestion Trace Log to analyze data lineage flows and identify potential architectural bottlenecks:
[Bastion-RAG 0: Virtual Emulator Ingestion Trace Log]
- [emulator/Sentinel-IN] INFO: Prompt input validated. Status: PASSED. Injection score: 0.05[cite: 7]
- [emulator/Vault-Phase1] INFO: Multi-strategy anonymization executed.[cite: 6]
- Input matching: "Hong Gildong" -> KR_NAME_8f3d2a (PERSON)[cite: 7]
- Input matching: "hong@naver.com" -> EMAIL_c3a91f (EMAIL)[cite: 7]
- [emulator/Navigator] INFO: Executing structural pre-filtering isolation.
- Injected filters: tenant_id=acme, collections=[customer_docs][cite: 7]
- [emulator/Anchor-IN] INFO: Differential noise injection executed. Sigma applied: 0.01
- [emulator/Vault-Phase2] INFO: Evaluating selective detokenization via OPA policy rules.
- [emulator/Sentinel-OUT] INFO: Grounding and hallucination checks completed. Status: PASSED.
4. Architectural Principles and Hard Constraints for Total Isolation
이번 문단은 아키텍처 원칙 문서(01_architecture-principles.md)에 포함될 핵심 제약 조건들을 다루고 있습니다. 도입부의 극적인 서사(Hammered out, intense technical debates)와 규격 본문의 과장된 표현(Every single, cleanly passed directly, even a single millisecond)을 모두 제거했습니다.
아키텍처 규칙서 본연의 목적에 맞춰, 명확한 엔지니어링 제약 조건과 동작 사양만 서술한 가장 담백하고 엄격한 기술 명세 톤(Dry & Hard Specification)으로 다듬은 영문입니다.
The architectural constraints of the Bastion-RAG framework are defined as follows:
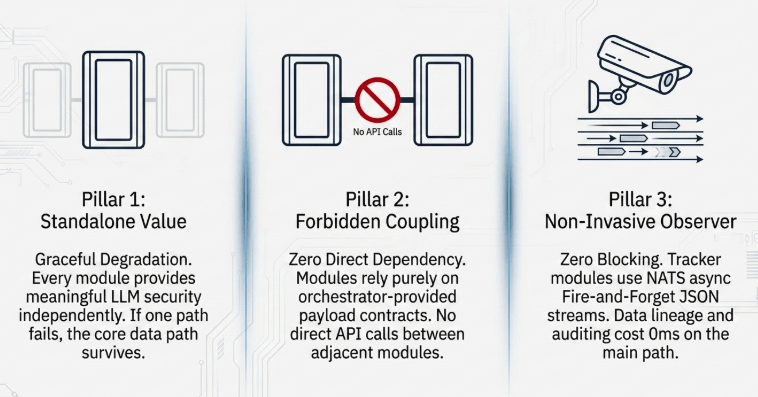
Core Functional Autonomy
Each module must be designed as a self-contained, autonomous unit that delivers security value independently when integrated with an LLM. To ensure graceful degradation, the failure of peripheral modules must not disrupt or cause cascading errors in the primary data path.
Prohibition of Direct Coupling
Modules must not instantiate or execute direct API calls to other modules. For example, the Navigator search layer does not maintain a reference to the Vault. It operates on a zero-trust data contract, where required user permission tokens are retrieved by the upstream orchestrator and included directly in the request payload.
Non-Invasive Observability Architecture
The Tracker module, which aggregates system audit records and maps data lineage paths, must not introduce synchronous blocking or latency to the primary data path. It functions as a non-invasive observer, consuming asynchronous, fire-and-forget JSON event streams transmitted over a decoupled NATS message bus.
5. Conclusion: The AI Assistant Is an Incredible Debating Partner, Not a Blindly Trusted Tool
The initial development phase required significant architectural iteration, as a standard microservice pattern failed to meet enterprise latency constraints. To resolve this, the process utilized the AI assistant to enforce explicit latency targets and language-specific ecosystem boundaries, resulting in the modular polyglot topology (v3).
The initial design phase involved four weeks of prototyping. An early implementation version introduced a dependency flaw, requiring a rollback and a two-week refactoring cycle. Managing these constraints provided practical insight into addressing LLM limitations, such as token context limits and context window degradation.
This process was technically comparable to previous large-scale architectural refactoring projects, which included reducing a legacy codebase footprint to one-fifth of its size and converting a one-month manual verification deployment cycle into a three-hour automated validation pipeline. Both experiences demonstrate that complex enterprise software design relies heavily on structured re-engineering and comprehensive automated testing.
Developing the Bastion-RAG framework provided practical insight into collaborative engineering with LLMs, demonstrating that managing new application development paradigms effectively depends on software engineering fundamentals and strict architectural control.