사실 나에게 내가 가장 처음 보안에 대해 진지하게 생각하게 된 것은 접근제어 분야에 대한 프로그래밍 구현을 시작하면서 입니다. 그래서 그런지 “논리적 파티셔닝” 이란 단어 듣는 순간 처음 생각된게 MAC, RBAC, …같은 여러 접근제어 체계를 생각했습니다. 제가 처음 보안 제품 개발을 한게 이런 접근제어 체계를 구현해보고, 비교해보고, 병합해보면서 시작 했죠. 처음에는 이런 체계는 실제 환경에서 얼마나 잘 쓰일수 있을까? 고민을 많이 했습니다. 사실 그래서 보안 운영을 시작해서 경력이 엉망이 되긴했지만… 지금 정리해보니 20년간 알게 모르게 조금씩 트렌드 변화가 있었는데 제가 모르고 있었네요.
어떻든 좀 많이 다르긴한데 그 다른점을 기준으로 설명을 풀어가보겠습니다.
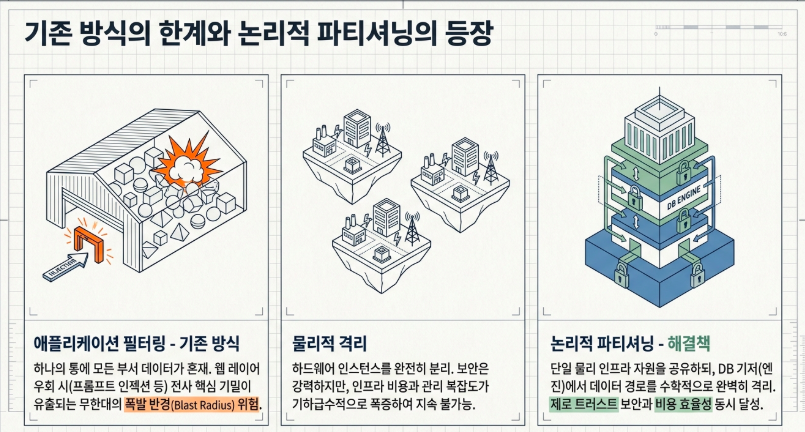
흔히 전통적인 소프트웨어 공학에 익숙한 엔지니어들은 데이터 격리를 떠올릴 때, 애플리케이션 레이어에서 런타임에 사용자 권한을 체크해 데이터를 걸러내는 일반적인 ‘필터 기반 권한 제어(Filter-driven Access Control)’를 생각하거나, 혹은 완전히 독립된 하드웨어 인스턴스를 할당하는 ‘물리적 격리(Physical Isolation)’를 떠올립니다. 하지만 비결정론적으로 작동하는 AI 생태계와 고차원 벡터 데이터베이스(Vector DB) 환경에서 전자는 해커의 정교한 간접 프롬프트 인젝션(Indirect Prompt Injection) 앞에 폭발 반경(Blast Radius)이 전사로 확산되는 치명적인 무력함을 보이며, 후자는 인프라 비용과 관리 복잡도를 기하급수적으로 폭증시키는 지속 불가능성을 낳습니다.
이 두 가지 극단적인 갈림길 사이에서 데이터의 활용 효율성을 극대화하는 동시에 물리적 격리 수준의 강력한 제로 트러스트(Zero Trust) 보안성을 성취하는 인프라적 해법이 바로 ‘논리적 파티셔닝(Logical Partitioning)’입니다. [The AI Shield] 시리즈의 여덟 번째 주제인 이번 포스팅에서는, 수천 가지의 전사 권한 교집합으로 인해 발생하는 ‘인덱스 파편화 지옥(Partition Fragmentation Hell)’을 선형 대수 기하학적 라우팅과 원자적 비트마스크(Bitmask) 연산으로 돌파하는 고도화된 방어 아키텍처를 생각하고 분석해 보겠습니다.

시리즈명: [The AI Shield] 고도화된 AI 보안과 데이터 거버넌스 아키텍처
- 시스템 설정 및 필터링
- 데이터 엔지니어링 및 전처리
- 수학적 최적화 및 고도화된 방어
- 임베딩 노이즈 주입
- 논리적 파티셔닝 (Here!)
- 임베딩 모델 편향성 검증
- Honey-token 주입
목차
1. 전통적 권한 제어의 한계와 논리적 파티셔닝의 개념적 정의
실무 설계를 진행할 때 많은 엔지니어들이 던지는 첫 번째 의문은 “기존의 Role-Based Access Control(RBAC)이나 조건문 필터링과 대체 무엇이 다른가?”입니다. 이 두 기법의 본질적인 차이는 보안 장벽의 붕괴 시 발생하는 데이터 유출의 ‘폭발 반경 차단’에 있습니다.
1.1 데이터 혼재와 필터 기반 권한 제어의 구조적 취약점
전통적인 권한 제어는 하나의 거대한 벡터 데이터베이스 통 안에 인사팀, 개발팀, 재무팀의 모든 문서를 한데 섞어 적재합니다. 사용자가 질문을 던지면 중간의 애플리케이션 서버가 사용자의 세션을 확인한 뒤, 쿼리문 뒤에 WHERE 부서 == 개발팀과 같은 메타데이터 필터를 동적으로 덧붙여 결과물만 걸러서 보여주는 방식(Filter-driven)입니다.
이 구조는 평상시에는 정상 작동하는 것처럼 보이지만, 악의적인 공격자가 탈옥(Jailbreaking) 공격이나 역공학 기법을 통해 애플리케이션의 웹 레이어 보안 가드레일을 우회하는 순간 완전히 무너집니다. 모든 부서의 데이터가 고차원 공간 내에 물리적으로 결합되어 혼재해 있기 때문에, 문지기(필터) 하나만 뚫리면 해커는 자신의 인가 범위를 초과하여 기업 전사의 핵심 기밀 자산 전체를 가로챌 수 있는 최악의 크로스 테넌트 유출(Cross-Tenant Leakage)을 허용하게 됩니다.
1.2 기하학적 인프라 레이어 방벽으로서의 논리적 파티셔닝
반면 논리적 파티셔닝은 보안 장벽의 위치를 소프트웨어 애플리케이션 코드가 아닌, 데이터베이스 엔진과 인프라 기저(수학적 연산 수준)로 격하시켜 배치하는 기술입니다. 단일 물리 인덱스 리소스를 공유하되, 데이터가 메모리에 적재되고 근사 근접 이웃(ANN) 검색이 수행되는 경로 자체를 기하학적 방(Partition) 단위로 완벽하게 쪼개어 관리합니다.
사용자가 AI에게 질문을 던지는 순간, 엔진은 전체 인덱스를 탐색하는 것이 아니라 사용자가 인가받은 특정 논리적 파티션 통로로만 쿼리를 강제 라우팅(Routing-driven)시킵니다. 설령 해커가 상위 웹 애플리케이션 가드레일을 완벽히 우회하더라도, 쿼리가 작동하는 기하학적 경계 자체가 특정 부서 구역 안에 갇혀 있으므로 타 부서 데이터의 존재 자체를 인지할 수 없으며 폭발 반경은 해당 파티션 내부로 철저히 제한됩니다.
2. 공통 데이터 중복 적재 난제와 다중 공간 라우팅 해법
논리적 파티셔닝을 실제 엔터프라이즈 RAG 환경에 적용할 때 아키텍트들이 마주하는 첫 번째 거버넌스 딜레마는 바로 ‘여러 부서가 동시에 참조해야 하는 공통 데이터의 처리 방식’입니다.
2.1 무분별한 데이터 복제가 야기하는 거버넌스 붕괴
사내 보안 가이드라인이나 전사 공통 취업규칙 같은 문서들은 인사팀, 개발팀, 재무팀 모두가 상시 참조해야 하는 데이터입니다. 만약 파티션 간의 완벽한 격리를 위해 이 공통 데이터를 [인사팀 파티션], [개발팀 파티션], [재무팀 파티션]에 각각 복사하여 집어넣는 방식을 취한다면 이는 최악의 하책(下策)이 됩니다.
데이터가 무분별하게 복제(Replication)되는 순간, 우리가 Part 6에서 그토록 강조했던 데이터 리니지(Data Lineage) 추적 체계는 완전히 파괴됩니다. 소스 문서가 업데이트되었을 때 수많은 파티션 내부의 벡터 좌표들을 동시에 동기화하는 과정에서 정합성 오류가 필연적으로 발생하며, 시스템 내부에 파편화된 복제본들이 통제 없이 확산되어 심각한 거버넌스 리스크를 초과하게 됩니다.
2.2 단일 소스(Single Source of Truth) 유지를 위한 다중 공간 라우팅
이 단절을 해결하기 위해 논리적 파티셔닝은 공통 데이터를 각 방에 복제하지 않고, 공통 자산만을 전담하는 독립된 ‘전사 공통 파티션(Common Partition)’ 방을 개설합니다. 그리고 런타임에 데이터를 복제하는 대신, 사용자의 권한 조합에 따라 쿼리의 경로를 동적으로 엮어내는 ‘다중 공간 라우팅(Dynamic Multi-Routing)’ 아키텍처를 전개합니다.
[User: R&D Staff] ──> [Middleware Policy Gate]
│
├──> Route to [R&D Atomic Partition]
└──> Route to [Common Shared Partition]
개발팀 직원이 질문을 던지면, 미들웨어 정책 엔진이 실시간으로 개입하여 해당 쿼리를 [개발팀 전용 파티션]과 [전사 공통 파티션]이라는 두 개의 격리된 방에만 동시에 브로드캐스팅합니다. 결과적으로 똑같은 마스터 데이터는 시스템 내부에 단 하나만 존재(Single Source of Truth)하여 파편화를 원천 차단하면서도, 사용자별로 독립된 논리적 데이터셋을 실시간으로 안전하게 조합해 내는 유연성을 획득합니다.
3. 인덱스 파편화 지옥(Partition Fragmentation Hell)의 메커니즘
공통 파티션 분리를 통해 중복 적재 문제를 해결하고 나면, 데이터 엔지니어는 곧이어 더 무서운 대규모 인프라 붕괴 위험인 ‘인덱스 파편화 지옥’을 마주하게 됩니다.
3.1 조합 가능한 권한의 폭증과 수학적 한계
엔터프라이즈 환경의 권한 체계는 단순하지 않습니다. 소속 부서(인사, 개발, 재무, 법무 등)뿐만 아니라 직급(사원, 대리, 부장, 임원), 프로젝트별 참여 권한(Project A, B, C), 그리고 보안 인가 등급(1급, 2급, 일반) 등 수많은 준식별자 속성들이 복합적으로 얽혀 있습니다.
만약 이 수많은 권한 조합의 교집합마다 독립된 논리적 파티션 방을 일일이 개설하려 든다면 어떻게 될까요? ‘2급 비밀 권한을 가진 인사팀이면서 Project A에 참여하는 임원용 파티션’과 같은 방식으로 방을 쪼개기 시작하면 시스템 내부에 수천 개의 미세 파티션이 생겨나게 됩니다.
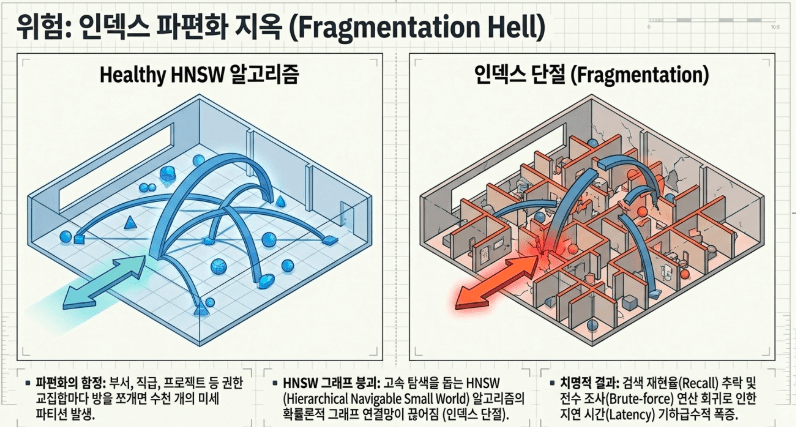
3.2 HNSW 인덱싱 알고리즘의 확률론적 붕괴와 지연 시간 폭증
파티션의 개수가 수천 개로 파편화되면, 벡터 데이터베이스의 초고속 검색을 책임지는 HNSW(Hierarchical Navigable Small World) 알고리즘의 그래프 구조가 완전히 망가집니다.
HNSW 인덱스는 고차원 공간 내에 데이터 노드 간의 근접 고속도로 연결망을 촘촘히 엮어 로그 단위 복잡도 $O(\log N)$로 순간 점프하는 확률론적 그래프입니다. 그러나 공간이 수천 개의 미세한 논리적 격벽으로 파편화되면, 상위 레이어에서 하위 레이어로 하강하며 근사 근접 이웃(ANN)을 탐색하는 과정에서 그래프의 연결 고리가 끊어지는 ‘인덱스 단절 현상’이 발생합니다. 이로 인해 검색 재현율(Recall)이 급격히 저하되거나, 끊어진 그래프를 메우기 위해 시스템이 전수 조사(Brute-force) 연산으로 회귀하면서 쿼리 지연 시간(Latency)이 기하급수적으로 폭증하여 전체 AI 인프라가 마비되는 재앙을 초래합니다.
4. 원자적 파티션(Atomic Partition)과 실시간 비트마스크(Bitmask) 최적화 아키텍처
이 파편화 지옥을 방지하고 수천 개의 권한 교집합을 완벽하게 수용하기 위해, 현대 엔터프라이즈 AI 아키텍처는 교집합 방을 만들지 않습니다. 대신 물리적 방의 개수를 최소화하는 ‘원자적 파티션’과 고속 ‘비트마스크 연산’의 결합 모델을 채택합니다.
4.1 원자적 파티션(Atomic Partition)의 최소화 설계
더 이상 쪼개질 수 없는 비즈니스 도메인의 최하위 기본 단위만 파티션 방으로 개설합니다. 부서 단위(인사팀방, 개발팀방)와 전사 공통 영역(공통방) 정도로만 논리적 격벽을 제한하여, 시스템 전체의 파티션 개수를 수십 개 이내의 안정적인 스케일로 강력하게 통제합니다. 데이터는 복제 없이 자신의 원자적 부서 방에 딱 한 번만 적재됩니다.
4.2 선형 대수 레이어 내 비트마스크(Bitmask) 결합 연산
수천 가지의 정교한 세부 보안 등급과 프로젝트 교집합 권한은 파티션의 개수를 늘리는 대신, 벡터 검색 엔진의 심층 레이어 내부에서 실시간 이진 비트 연산을 통해 해결합니다.
데이터가 원자적 파티션에 인젝션될 때, 각 데이터 청크(Chunk)의 메타데이터 필드에는 보안 속성을 압축한 고속 고정 길이 비트 시퀀스가 할당됩니다. 사용자가 질문을 던지는 순간의 매커니즘은 다음과 같이 수행됩니다.
- 초기 라우팅: 사용자가 ‘2급 비밀 권한을 가진 개발팀 직원’이라면 쿼리는 오직
[개발팀 원자적 파티션]과[전사 공통 파티션]두 곳으로만 제한적으로 날아갑니다. 타 부서 방은 탐색 대상에서 원천 배제되므로 보안 유출 폭발 반경이 1차 차단됩니다. - HNSW 탐색 내부에서의 비트 필터링:
[개발팀 파티션]그래프 내부에서 고속 탐색이 수행될 때, 벡터 엔진은 거리를 계산하는 연산 루프 내부에서 CPU 하드웨어 친화적인 가속 비트 연산(Bitwise AND)을 동시에 수행합니다.
$$P_{\text{grant}} \ \& \ P_{\text{doc}} == P_{\text{doc}}$$
- 사용자의 인가 비트 ($P_{\text{grant}}$):
1010(개발팀 인가 ON, 2급 비밀 인가 ON) - 일반 개발 문서의 보안 비트 ($P_{\text{doc1}}$):
1000(개발팀 인가 ON, 2급 비밀 인가 OFF) $\rightarrow$ 연산 결과 일치 (통과/검색 포함) - 1급 비밀 R&D 문서의 보안 비트 ($P_{\text{doc2}}$):
1100(개발팀 인가 ON, 1급 비밀 인가 ON) $\rightarrow$ 연산 결과 불일치 (즉시 탈락)
이 기법을 도입하면 HNSW 그래프의 연결성을 완벽하게 보존하여 단 몇 밀리초(ms) 만에 초고속 벡터 검색을 완수하는 동시에, 수천 개의 복잡한 권한 교집합 필터링을 완벽하게 수행할 수 있습니다. 엔지니어가 우려하던 인덱스 파편화 지옥을 수학적으로 완벽히 우회하는 최적화 구조입니다.
5. 글로벌 AI 컴플라이언스 만족과 제로 트러스트 감사 체계
엔터프라이즈 환경에서 원자적 파티셔닝과 비트마스크 아키텍처를 유지하는 것은 기술적 최적화를 넘어, 글로벌 주요 AI 법률의 보안 통제 요건을 충족하기 위한 강력한 법적 증거 자료가 됩니다.
5.1 EU AI Act의 데이터 거버넌스 및 엄격한 격리 입증 의무
EU AI Act 및 ISO/IEC 42001 거버넌스 가이드라인은 고위험 AI 시스템이 사용하는 데이터 가공 파이프라인 전반에 대해 자산의 오인 추출 및 무단 접근을 방지하는 명확한 ‘기술적 보호 장치’를 구축할 것을 법적으로 강제하고 있습니다.
애플리케이션 소스코드 레벨의 단순 필터링은 코드 수정이나 개발자의 실수에 의해 무력화될 위험이 상존하므로, 규제 기관의 철저한 거버넌스 감사를 통과하기 어렵습니다. 반면 인프라 수준에서 쿼리 경계 자체를 제한하는 원자적 파티셔닝 아키텍처는 데이터 유출 리스크가 하드웨어 및 엔진 레이어에서 논리적으로 차단되어 있음을 시각적·구조적으로 증명할 수 있어 컴플라이언스 준수 능력을 극대화합니다.
5.2 제로 트러스트(Zero Trust) 감사 추적과 불변성 로깅
원자적 파티셔닝과 결합된 다중 공간 라우팅 엔진은 모든 쿼리 요청이 발생할 때마다 사용자의 권한 비트 플래그와 실제 접근한 파티션 ID의 일치 여부를 타임스탬프와 함께 암호화된 불변 로그(Immutable Log) 형태로 기록해야 합니다. 이 기록은 사후 보안 감사 시 특정 테넌트나 권한 그룹의 사용자가 허가받지 않은 비밀 파티션 영역에 절대 접근할 수 없었음을 수학적으로 완벽히 입증하는 핵심 거버넌스 감사 추적(Audit Trail)의 근거로 기능합니다.
6. 데이터 보안 아키텍트를 위한 논리적 파티셔닝 실무 체크리스트
실무 프로덕션 환경에서 파편화 지옥을 예방하고 안전한 원자적 파티셔닝 체계를 안착시키기 위해, 데이터 보안 책임자가 점검해야 할 10대 아키텍처 핵심 체크리스트입니다.
| 점검 항목 | 실무 확인 사항 및 감사 기준 |
| 1. 파티션 최소화 표준 | 교집합 파티션 생성을 엄격히 금지하고, 도메인별 ‘원자적 파티션’으로 개수를 통제했는가? |
| 2. 다중 공간 라우팅 구현 | 공통 데이터 복제를 배제하고, 공통 파티션을 활용한 동적 다중 라우팅 미들웨어를 구축했는가? |
| 3. 비트마스크 스키마 설계 | 전사의 복잡한 권한 조합을 고속 이진 연산할 수 있는 고정 길이 비트 플래그 시스템을 정립했는가? |
| 4. 엔진 레벨 결합 연산 | 비트마스크 필터링이 앱 코드가 아닌 벡터 DB 엔진 내부 연산(HNSW 탐색 루프)과 결합되어 작동하는가? |
| 5. 폭발 반경 차단 검증 | 특정 부서 파티션 내에서 보안 취약점이 발생하더라도 타 부서 파티션 데이터는 격리되는가? |
| 6. HNSW 인덱스 재현율 측정 | 원자적 파티셔닝 적용 후, 대규모 쿼리 시 검색 재현율(Recall) 저하가 없는지 벤치마크를 수행했는가? |
| 7. 동적 세션 토큰 연동 | 사용자의 권한 비트 플래그가 조작 불가능하도록 Identity Provider(IdP)의 단기 JWT 토큰과 연동되는가? |
| 8. 하드웨어 가속 최적화 | 대량의 비트 연산 처리를 위해 SIMD(Single Instruction Multiple Data) 등 CPU/GPU 하드웨어 가속을 활성화했는가? |
| 9. 파기 및 offboarding 보장 | 특정 프로젝트 종료 나 테넌트 해지 시 해당 원자적 파티션 전체를 안전하게 Hard Delete 할 수 있는가? |
| 10. 컴플라이언스 실시간 모니터링 | 허가되지 않은 파티션 구역으로의 라우팅 시도 발생 시 즉시 감지하여 SIEM 경보를 발생시키는가? |
결론: 영리한 기하학적 격리가 성취하는 대규모 AI 인프라의 투명성
논리적 파티셔닝의 핵심은 데이터 보호를 위해 비싼 물리 인프라를 무한정 쪼개어 증설하는 비용 낭비를 범하지 않는 것에 있습니다. 동시에, 데이터들을 한 통에 무책임하게 섞어두고 애플리케이션의 얇은 필터 코드 하나에 기업의 명운을 걸지 않는 엄밀함에 있습니다.
원자적 단위로 파티션의 크기를 영리하게 제어하고, 그 내부에서 고속 비트마스크 연산의 수학적 장벽을 결합하는 아키텍처만이 대규모 RAG 시스템이 가진 인프라 가용성(속도 및 비용 최적화)을 100% 누리면서도 최고의 보안성(Privacy)을 동시에 성취하는 유일한 이정표입니다. 이 기하학적 격리 레이어가 파이프라인 기저에 완벽히 안착될 때, 생성형 AI 시스템은 비로소 보안의 불확실성을 걷어내고 가장 안전하고 투명한 엔터프라이즈 자산으로 작동할 것입니다.
다음 포스팅에서는 [The AI Shield] 시리즈의 아홉 번째 주제이자 고도화된 방어 단계의 세 번째 관문인 ‘임베딩 모델 편향성 검증(Embedding Model Bias Verification)’ 기술을 상세히 분석해 보겠습니다. 우리가 사용하는 상용 및 오픈소스 임베딩 모델 내부의 가중치 자체에 특정 국가, 인종, 혹은 기업 내 특정 부서에 유리하도록 치우쳐진 기하학적 왜곡(Bias)이 존재하는지 수학적으로 판별하고, 이를 데이터 전처리 단계에서 보정하는 고급 편향 통제 전략을 소개해 드리겠습니다.
여기까지 글을 적어보면서 한가지 프로젝트를 생각하게 됬습니다. 간단한 보안용 RAG를 하나 만들어볼까 합니다. 제가 생각하는 것보다 LLM에도 여러 보안 사항을 적용할 수 있는 것 같아서 정말 간단하게 만들어서 개념을 공부할 수 있고 작은 LLM에 적용할수 있게 만들어보려고 합니다.