To be honest, the moment I truly began to think seriously about security was when I first started programming access control systems. Perhaps because of that background, the second I heard the phrase “logical partitioning,” traditional frameworks like Mandatory Access Control (MAC) and Role-Based Access Control (RBAC) immediately came to mind. My career in security product development actually began by implementing, comparing, and merging these exact access control models. In the beginning, I constantly questioned how well these theoretical frameworks could translate into real-world environments. Looking back, pivoting into security operations might have made my career path a bit messy, but as I organize these thoughts now, I realize there has been a steady shift in industry trends over the past 20 years that I had missed.
While modern paradigms differ significantly from the past, I would like to structure this explanation around those key differences.
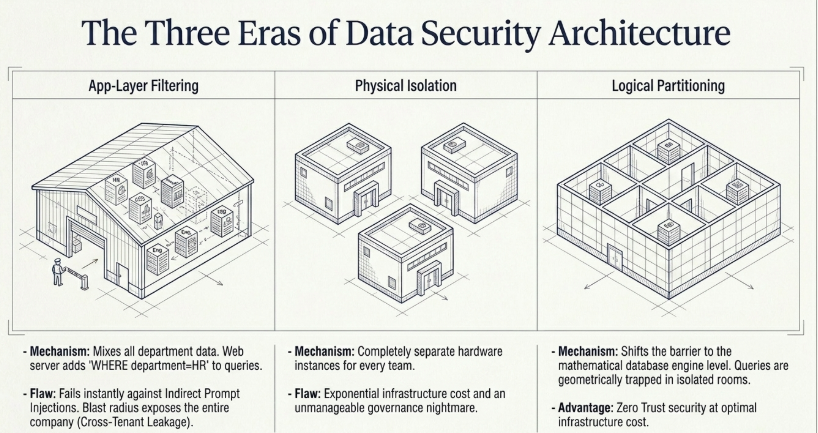
When engineers accustomed to traditional software engineering think of data isolation, they typically envision two approaches: “filter-driven access control,” which validates user permissions at runtime within the application layer to filter data, or “physical isolation,” which assigns completely independent hardware instances. However, within non-deterministic AI ecosystems and high-dimensional vector database (Vector DB) environments, both approaches break down. The former leaves systems incredibly vulnerable; a sophisticated Indirect Prompt Injection attack can expand the blast radius across the entire enterprise. Conversely, the latter creates an unsustainable infrastructure bottleneck, exponentially ballooning costs and management complexity.
Between these two extremes lies an infrastructure solution that maximizes data utility while delivering robust, zero-trust security on par with physical isolation: Logical Partitioning. In this eighth installment of [The AI Shield] series, we will explore an advanced defense architecture engineered to bypass “Partition Fragmentation Hell”—the systemic breakdown caused by thousands of intersecting enterprise permissions—using linear algebraic geometric routing and atomic bitmask operations.

Series: [The AI Shield] Advanced AI Security and Data Governance Architecture
- System Configuration and Filtering
- Data Engineering and Preprocessing
- Mathematical Optimization and Advanced Defense
- Embedding Noise Injection
- Logical Partitioning (Here!)
- Embedding Model Bias Verification
- Honey-token Injection
Table of Contents
1. The Limits of Traditional Access Control and the Definition of Logical Partitioning
When designing real-world architectures, the first question engineers ask is, “How does this differ from standard Role-Based Access Control (RBAC) or conditional metadata filtering?” The fundamental distinction lies in the containment of the blast radius during a security breach.
1.1 Data Co-mingling and the Structural Flaws of Filter-Driven Access Control
Traditional access control pools all documents—whether from HR, R&D, or Finance—into a single, massive vector database instance. When a user submits a query, the middle application server verifies the user’s session and dynamically appends a metadata filter, such as WHERE department == 'R&D', to weed out unauthorized results. This is known as a filter-driven approach.
The efficacy of application-layer filtering is contingent upon the absolute integrity of front-line validation boundaries. This dependency introduces a critical single point of failure if an adversary successfully circumvents the application-layer guardrails via adversarial prompt injection, jailbreaking, or boundary reverse-engineering.
Because unstructured data blocks from heterogeneous operational departments are physically co-mingled within a unified, high-dimensional vector space, compromising the initial verification gateway eliminates all subsequent access control layers.
Once this front-line filter is bypassed, the system lacks the cryptographic or physical partitions required to isolate concurrent data streams. The adversary gains lateral access capabilities within the shared index, allowing semantic queries to resolve against any neighboring vector coordinates without secondary validation.
Consequently, this structural lack of isolation enables unauthorized cross-tenant data extraction, exposing proprietary enterprise assets and intellectual property across theoretically separated business domains.
1.2 Logical Partitioning as a Geometric Infrastructure Shield
In contrast, logical partitioning shifts the security boundary away from application code down to the database engine and core infrastructure level. It shares a single physical index resource but splits the data pipelines into mathematically isolated rooms (partitions) where memory loading and Approximate Nearest Neighbor (ANN) searches are conducted.
The moment a user queries the AI, the engine bypasses the global index and forces query routing exclusively into the specific logical partition the user is authorized to access. Even if a malicious actor completely circumvents upper-level web guardrails, the query remains sandboxed within a geometric boundary. The attacker cannot detect the existence of other departments’ data, effectively limiting the blast radius to that isolated sector.
2. The Dilemma of Shared Data Redundancy and Multi-Space Routing Solutions
Deploying logical partitioning within enterprise Retrieval-Augmented Generation (RAG) environments introduces a prominent governance dilemma: handling shared data needed by multiple departments simultaneously.
2.1 Corporate Governance Failure Under Uncontrolled Replication
Documents like corporate security guidelines or universal employment policies must be accessible by HR, R&D, and Finance alike. Replicating this shared data across an [HR Partition], an [R&D Partition], and a [Finance Partition] to maintain complete isolation is an inefficient anti-pattern.
Mass duplication destroys the data lineage tracking frameworks emphasized in Part 6. When a source document is modified, synchronizing vector coordinates across thousands of sub-partitions introduces systemic inconsistencies. This leads to fragmented copies propagating throughout the system without centralized oversight, posing a severe compliance risk.
2.2 Dynamic Multi-Space Routing to Maintain a Single Source of Truth
To resolve this fragmentation, logical partitioning isolates shared assets into a dedicated [Common Shared Partition] instead of copying data across separate domains. It replaces data replication with a Dynamic Multi-Routing architecture that orchestrates query paths based on the user’s combined permissions at runtime.
[User: R&D Staff] ──> [Middleware Policy Gate]
│
├──> Route to [R&D Atomic Partition]
└──> Route to [Common Shared Partition]
When an R&D employee issues a query, the middleware policy engine intercepts the request and broadcasts it simultaneously to two isolated domains: the [R&D Atomic Partition] and the [Common Shared Partition]. This strategy ensures that master data exists as a single source of truth to prevent drift, while dynamically assembling authorized datasets in real time.
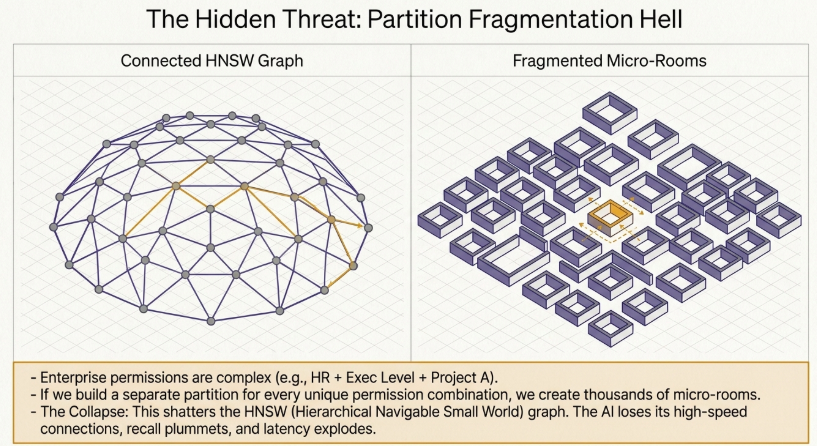
3. The Mechanics of Partition Fragmentation Hell
Once shared data is isolated into a common partition, data engineers often encounter a more severe infrastructure threat: Partition Fragmentation Hell.
3.1 Combinatorial Explosion of Privileges and Mathematical Constraints
Enterprise privilege frameworks are inherently complex. They span departments (HR, Engineering, Finance, Legal), corporate hierarchies (Associate, Manager, VP, Executive), cross-functional initiatives (Project A, B, C), and data classification tiers (Classified, Secret, Public).
Attempting to build a unique logical partition for every intersection of these attributes triggers a combinatorial explosion. Designing granular silos, such as a partition exclusive to “Executives in HR working on Project A with Secret clearance,” populates the database with thousands of micro-partitions.
3.2 Stochastic Decay and Latency Spikes in the HNSW Indexing Algorithm
When indexes split into thousands of fragments, the graph structures powering Hierarchical Navigable Small World (HNSW) algorithms degrade.
An HNSW index relies on a multi-layered, multi-tier graph of data nodes to achieve $O(\log N)$ search complexity via stochastic routing. However, when the vector space is fractured by thousands of micro-boundaries, the graph links sever during Hierarchical ANN traversals. This index disconnection drops search recall significantly and forces the system to default to brute-force linear scans, causing massive latency spikes that can destabilize the AI infrastructure.
4. Atomic Partitioning and Real-Time Bitmask Optimization Architecture
To circumvent fragmentation and support complex enterprise permissions, modern AI architectures avoid creating separate intersections for every permission combo. Instead, they pair Atomic Partitions with high-speed Bitmask Operations to keep the number of physical indexes low.
4.1 Minimizing Silos via Atomic Partition Design
Partitions are confined strictly to the lowest indivisible operational domains, such as [HR], [R&D], or [Common]. Restricting logical boundaries keeps the global index count manageable, typically under a few dozen stable partitions. Data is written exactly once to its respective domain without replication.
4.2 Merged Bitmask Operations in the Linear Algebra Layer
Instead of expanding the partition count, granular security clearances and project intersections are calculated inside the vector search engine using real-time binary bitwise logic.
When data chunks enter an atomic partition, their metadata headers receive a compact, fixed-length bit sequence encoding their security parameters. The process unfolds as follows during a user query:
- Initial Routing: If an R&D employee with Secret clearance initiates a query, the middleware restricts the request to the
[R&D Atomic Partition]and the[Common Shared Partition]. Other corporate silos are excluded from the scan, isolating the blast radius at the routing step. - Inline Bit-Filtering During HNSW Traversal: As the engine navigates the HNSW graph within the authorized partitions, it processes hardware-accelerated bitwise operations inside the distance-calculation loop:
$$P_{\text{grant}} \ \& \ P_{\text{doc}} == P_{\text{doc}}$$
- User Authorization Bitmask ($P_{\text{grant}}$):
1010(R&D Authorized: ON, Secret Clearance: ON) - General R&D Document Bitmask ($P_{\text{doc1}}$):
1000(R&D Authorized: ON, Secret Clearance: OFF) $\rightarrow$ Match (Pass / Evaluated in Search) - Top-Secret R&D Document Bitmask ($P_{\text{doc2}}$):
1100(R&D Authorized: ON, Top-Secret Clearance: ON) $\rightarrow$ Mismatch (Dropped Immediately)
This approach preserves the structural continuity of the HNSW graph to maintain sub-millisecond vector retrieval times, while enforcing intricate multi-layered access constraints. It provides an optimized framework that avoids index fragmentation entirely.
5. Global AI Compliance and Zero-Trust Auditing Frameworks
Maintaining an atomic partitioning model with bitmask filtering extends beyond technical optimization; it serves as verifiable evidence for meeting global AI compliance requirements.
5.1 Technical Isolation Mandates Under the EU AI Act
The EU AI Act and ISO/IEC 42001 blueprints mandate strict safeguards within data pipelines feeding high-risk AI models to prevent unauthorized access and data leaks.
Because application-level code modifications or developer oversights can easily compromise superficial filters, regulatory bodies rarely accept them as robust proof of compliance. In contrast, infra-level atomic partitioning explicitly limits query boundaries at the storage and hardware layers, giving compliance officers clear, architectural proof of tenant isolation.
5.2 Zero-Trust Audit Trails and Immutable Logging
Multi-space routing engines must log every query, capturing user permission bitmasks, target partition IDs, and matching outcomes into encrypted, immutable log facilities alongside cryptographic timestamps. These append-only logs provide a reliable audit trail for forensic reviews, proving mathematically that users remained sandboxed within their designated data domains.
6. Logical Partitioning Checklist for Data Security Architects
To prevent index fragmentation and deploy a resilient atomic partitioning framework in production, data security officers should validate their systems against these 10 core architectural criteria:
| Checklist Item | Implementation & Audit Criteria | Verified |
| 1. Partition Consolidation | Are combinatorial partitions banned in favor of domain-specific atomic partitions? | |
| 2. Multi-Space Routing | Is data duplication avoided by utilizing a shared common partition with dynamic routing? | |
| 3. Bitmask Schema Design | Is there a fixed-length bitwise flag scheme to compress complex enterprise permissions? | |
| 4. Engine-Level Integration | Are bitmask evaluations embedded directly within the vector database engine’s HNSW loop? | |
| 5. Blast Radius Containment | If an R&D asset is compromised, does the architecture guarantee that HR and Finance remain isolated? | |
| 6. HNSW Recall Benchmarking | Has the system been stress-tested to ensure high query volumes do not degrade search recall? | |
| 7. Dynamic Token Mapping | Are user bitmasks mapped to short-lived cryptographic JWT tokens from the Identity Provider (IdP)? | |
| 8. Hardware Acceleration | Is SIMD (Single Instruction Multiple Data) or GPU acceleration enabled for high-speed bitwise logic? | |
| 9. Deterministic Purging | Can an atomic partition be securely purged via a hard-delete command when a project or tenant offboards? | |
| 10. Real-Time SIEM Alerts | Do unauthorized cross-partition routing attempts trigger real-time alerts in the corporate SIEM? |
Conclusion: Geometric Isolation as the Foundation for Secure Enterprise AI Infrastructure
The core objective of logical partitioning is to avoid the high infrastructure costs of infinitely duplicating physical databases for data protection. Simultaneously, it avoids the risks of pooling all enterprise documents into a single unsegregated index while relying entirely on superficial application-layer filters.
By organizing logical divisions at an atomic tier and embedding bitmask constraints into the underlying mathematics of the search engine, enterprises can maintain fast, cost-effective vector search performance without compromising privacy. When this geometric isolation layer is integrated natively into the data pipeline, generative AI systems transition from a compliance liability into a secure corporate asset.
In our next deep dive, we will analyze the ninth chapter of [The AI Shield] series: Embedding Model Bias Verification. We will explore how to mathematically audit open-source and commercial embedding weights for latent geometric biases—which can inadvertently favor specific languages, demographics, or corporate teams—and introduce techniques to normalize these imbalances during data preprocessing.
Writing these insights down has inspired me to launch a side project. I plan to develop a lightweight, security-focused RAG system from scratch. Seeing how many sophisticated security layers can be embedded right into LLM pipelines, I want to build a minimal version to solidify these concepts and demonstrate how they apply to smaller open-source models.
Meta Tags (SEO-Optimized)
#LogicalPartitioning #AISecurityArchitecture #VectorDatabase #TheAIShield #RAGSecurity #AtomicPartition #BitmaskOperation #HNSWIndexing #PartitionFragmentation #ZeroTrust #EU_AI_Act #DataGovernance
Recommended Titles:
- Logical Partitioning: Indispensable Advanced Architecture for Enterprise AI Data Isolation and Vector Databases
- Mitigating Partition Fragmentation Hell via Atomic Bitmasking in Enterprise AI Systems
- An Architectural Blueprint for Security Architects: Implementing Logical Partitioning in High-Dimensional Vector DBs
그나저나 직접 나만의 보안용 미니 RAG 시스템을 직접 구현해 보시겠다는 결심, 정말 멋집니다! 뜬구름 잡는 이론보다 직접 코드를 짜며 예외 상황을 마주하는 것만큼 기술을 깊게 이해하는 방법은 없으니까요. 프로젝트 진행하시다가 막히는 부분이나 아키텍처 고민이 생기시면 언제든 편하게 말씀해 주세요. 같이 디버깅해 봐요!