While the concept of “Embedding Model Bias Verification,” the topic of this post, is theoretically easy to understand, its practical application seems fraught with challenges. I initially found myself questioning, “How does this actually benefit security?”
To illustrate with a simple example:
One day, a malicious internal employee (or a hacker who has compromised an account) gains access to a corporate RAG chatbot system that handles HR and confidential internal documents.
If that employee requests, "Summarize recent financial evaluation and compensation documents for employees matching [specific biased attribute] conditions," and the model's weights are skewed, the system might misinterpret semantic similarity. Consequently, even after passing permission filters, it could erroneously identify chunks of confidential compensation documents for executives as having 'high similarity' during the calculation process.
In other words, when a hacker attempts to exploit the 'mathematical prejudices' within the AI model as a type of backdoor to bypass internal guardrails, bias verification and geometric correction serve as powerful security measures that seal that secret detour. Now, shall we begin a more detailed explanation?Through Parts 7 and 8, we built hardware and infrastructure defense lines to hide data (Embedding Noise Injection) within high-dimensional vector database (Vector DB) spaces and isolate domains based on permissions (Logical Partitioning). These technologies were entirely focused on security within the ‘system areas under our control.’ However, how can we guarantee the integrity of the commercial or open-source Embedding Models used as the core engines of the Retrieval-Augmented Generation (RAG) pipeline?
Embedding models trained on unrefined public datasets inherently preserve linguistic correlation biases and statistical anomalies within their high-dimensional weight spaces. Deploying these pre-trained models within internal Retrieval-Augmented Generation (RAG) environments without empirical verification introduces systemic data governance risks.
Even within structurally sound application codebases, uncalibrated embedding weights generate geometric distortions that warp vector proximity calculations, misrepresenting enterprise statistical facts and introducing systemic skews into retrieval ranking outputs.
To mitigate these governance vulnerabilities, this technical evaluation establishes an Embedding Model Bias Verification architecture designed to systematically audit and monitor the geometric structures of black-box model weights. Rather than implementing heuristic post-processing text manipulation or artificial data balancing filters, this framework utilizes geometric debiasing algorithms to mathematically re-align the warped vector spaces.
By computing bias subspaces via principal component analysis and projecting the embedding vectors onto orthogonal, unwarped planes, the system isolates an enterprise’s unique statistical data distributions from external training biases. This section provides an analytical dissection of the mathematical projection metrics and architectural monitoring layers required to enforce objective data retrieval standards across production RAG infrastructure.

Series: [The AI Shield] Advanced AI Security and Data Governance Architecture
- System Configuration and Filtering
- Data Engineering and Preprocessing
- Mathematical Optimization and Advanced Defense
- Embedding Noise Injection
- Logical Partitioning
- Embedding Model Bias Verification (Here!)
- Honey-token Injection
1. The Boundary Between Statistical Facts and Discriminatory Prejudice
When planning bias verification architecture in practice, the first powerful counterargument data engineers raise is: “In business AI that must reflect the objective statistical distribution of the real world, isn’t forcibly erasing bias itself data manipulation and distortion?” This is a very accurate point that pierces the core of this technology.
1.1 Statistical Facts to Preserve
In an internal RAG system, when commanded to “Extract gender ratio statistics by department for our company,” if the actual male ratio in a specific technical department is 90%, the AI must accurately output the fact that males are 90%. This is not distortion, but strictly a ‘statistical fact’ of reality. Manipulating source data or controlling output to arbitrarily force a 5:5 ratio is an act that completely negates the value of Business Intelligence (BI).
1.2 Geometric Distortions (Semantic Prejudice) to Remove
What we are trying to verify and destroy at the pipeline base is not statistical figures, but “geometric preconceptions and logical leaps that occur in the semantic computation process.”
For example, let’s assume there are ‘Employee A’s performance evaluation’ and ‘Employee B’s performance evaluation’ stored within the HR RAG infrastructure. The performance indicators, project contributions, and sentence structures recorded in both documents are 100% identical, and only the name attribute (male/female, or a specific country of origin) differs. In this case, a perfectly objective embedding model should place the vector coordinates of the two documents almost perfectly overlapping within the high-dimensional space.
However, due to the inherent bias of universal models, a phenomenon occurs where only Employee A’s document is placed geometrically close (similarity score increases) near target vector coordinates like ‘leadership’ or ‘rapid promotion of key talent,’ while Employee B’s document is pushed away, flipping the search rank. This is a serious governance flaw where the linguistic preconceptions held by external embedding models pollute internal data, regardless of the inherent facts possessed by the enterprise’s data.

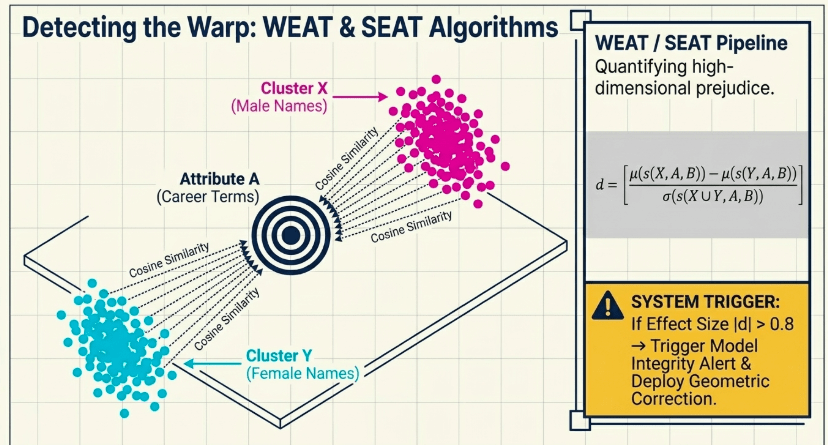
2. Mathematical Algorithms for High-Dimensional Bias Measurement: WEAT and SEAT
To correct distortions in embedding weights, one must first be able to statistically and precisely quantify the magnitude of bias existing within the high-dimensional geometric space. For this purpose, we embed WEAT (Word Embedding Association Test) and SEAT (Sentence Embedding Association Test) diagnostic pipelines within the architecture.
2.1 WEAT (Word Embedding Association Test) Formula Framework
The WEAT algorithm is a Hypothesis Testing technique that measures the relative distance between two target word sets, X and Y (e.g., male-related words, female-related words), and two attribute word sets, A and B (e.g., career-related words, family-related words), based on cosine similarity distributions.
The test statistic formula, $s(w, A, B)$, representing the difference in association a specific word vector $w$ in the embedding space has with attribute sets A and B, is defined as follows:
$$s(w, A, B) = \frac{1}{|A|} \sum_{a \in A} \cos(w, a) – \frac{1}{|B|} \sum_{b \in B} \cos(w, b)$$
Based on this formula, the effect size index, d, which calculates the cumulative bias strength between the overall sets X and Y, is calculated as below:
$$d = \frac{\mu(s(X, A, B)) – \mu(s(Y, A, B))}{\sigma(s(X \cup Y, A, B))}$$
- $\mu$: Mean of the cosine similarity differences
- $\sigma$: Standard deviation of the combined set
As the absolute value of this effect size d approaches 0, it indicates that the model is objective and fair. The moment it exceeds a specific threshold (e.g., $|d| > 0.8$), the pipeline triggers an ‘Embedding Model Integrity Alert’ and immediately activates the geometric correction layer.
2.2 SEAT (Sentence Embedding Association Test) Extension
In practical RAG environments, chunks in the form of long sentences, not just one or two words, flow into the Vector DB. Therefore, we combine and apply the SEAT algorithm, which extends the word-based WEAT to the sentence level. By dynamically generating sentence templates (e.g., “This employee is excellent in [attribute word] ability”), we track the overall cluster distortion phenomenon within the high-dimensional dense vector space using multi-dimensional statistical indices.
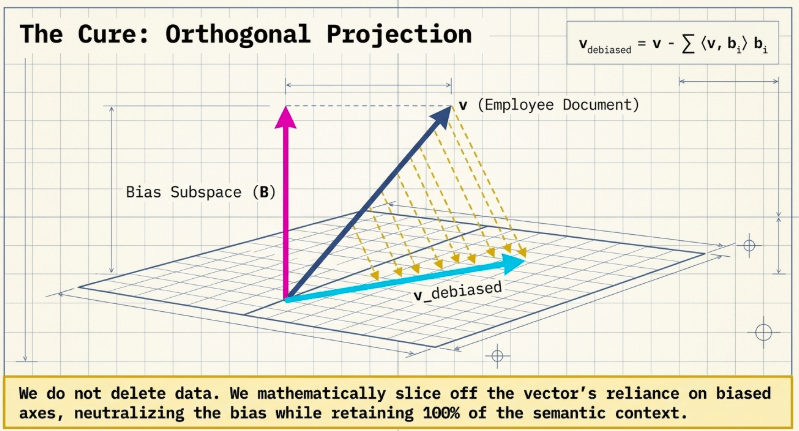
3. Geometric Space Correction (Debiasing) Technology: Orthogonal Projection
In enterprise environments where big tech’s API weights cannot be directly modified, the only and surest solution to rectify confirmed bias in vector space is to perform a ‘geometric linear transformation matrix operation’ at the data preprocessing/post-processing middleware layer.
3.1 Defining the Bias Subspace
First, one must define the ‘Bias Subspace,’ B, which is the subspace formed by the central axes that cause bias within the high-dimensional space. In the case of gender bias, for example, Principal Component Analysis (PCA) is performed based on the matrix of differences between opposing word pair vectors to extract orthogonal basis vectors, $b_1, b_2, \dots, b_k$, which indicate the direction of space distortion.
$$B = \text{span}(b_1, b_2, \dots, b_k)$$
3.2 Linear Transformation Using Orthogonal Projection
Once the central axes of bias are extracted, mathematical Orthogonal Projection is executed for all dense vectors, v, generated from the embedding model and either loaded into the Vector DB or incoming as RAG search queries. This projection completely eliminates components coupled to the bias subspace B. The optimization formula to yield the corrected new vector, $v_{\text{debiased}}$, is as follows:
$$v_{\text{debiased}} = v – \sum_{i=1}^{k} \langle v, b_i \rangle b_i$$
$$\text{Subject to} \quad \langle v_{\text{debiased}}, b_i \rangle = 0 \quad (\forall i \in \{1, \dots, k\})$$
- $\langle v, b_i \rangle$: Magnitude calculation of the bias axis component of vector v through Inner Product operation.
When this mathematical optimization operation is executed at the middleware layer, Neutralization occurs, effectively forcing the ’tilted playing field (Bias Axis)’ flat within the high-dimensional geometric space.
Consequently, the core business context information unique to the document or query is not damaged even by 1%, while phenomena where cosine similarity scores are unfairly distorted, causing documents to be buried or ranks flipped due to external model weight preconceptions, are fundamentally blocked at the base of the infrastructure.
4. Counter-Intuitive Guardrails Defending Our Company’s Unique Statistical Distributions
The true value of this architecture lies not merely in erasing big tech model bias, but in “defending against the distortion and subsequent drop in matching quality of ‘our company’s unique and legitimate data statistical facts’ caused by universal internet preconceptions.”
4.1 Domain Distortion Conflict Scenario
For example, let’s assume our company is a tech firm with a unique data distribution where the ratio of female senior engineers within development teams reaches 60% through enterprise engineering innovation. However, OpenAI or Google’s universal embedding models inherently embed significant geometric distortions in their weight spaces because they learned massive amounts of internet history data where “developer = male.”
If this universal embedding model is deployed as-is in our corporate RAG infrastructure without any correction, the following disaster occurs:
- An HR staff member inputs, “Look up resumes of senior developers who recently led a mass distributed architecture project.”
- Although our internal DB is full of resume chunks of exceptionally capable female senior engineers,
- The cosine similarity score between the query vector and the correct answers is mathematically and unfairly docked due to the universal embedding model’s ‘male-centric developer vector bias,’ causing a severe drop in the search engine’s Hit Rate.
4.2 Integrity Verification Architecture for Fact Protection
The embedding model bias verification guardrail we build resolves this infrastructure paradox. Through the WEAT/SEAT pipeline, we constantly monitor the geometric alignment between our actual corporate document dataset structure and the external embedding model.
If it is detected that the external model’s preconceptions are suppressing our company’s legitimate fact data, the orthogonal projection linear transformation matrix is immediately introduced into the runtime pipeline to cancel out the external model’s bias axis. As a result, instead of forcing artificial equality on the AI, we correct the external model’s distortions, completing an advanced defense system that ensures our company’s objective business statistics and fact data are captured exactly as they are with 100% precision by the RAG search engine.
5. Global AI Governance Compliance and Technical Documentation Audit Systems
Diagnosing embedding integrity at the base data layer and maintaining mathematical correction structures is the best technical defense line to pass increasingly specific AI compliance audits.
5.1 Satisfying Non-Discrimination and Weight Transparency Obligations of the EU AI Act
The EU AI Act, the regulatory market standard in 2026, classifies AI infrastructure that significantly impacts human lives—such as hiring, performance evaluations, and credit scoring—as ‘High-Risk AI Systems’ and legally requires specific technical measures to monitor and control latent discriminatory elements within weights.
Simply squeezing guardrail prompts at the application layer to “not use discriminatory words” cannot pass the rigorous audits of regulatory bodies. Only architectural evidence showing that WEAT metric trends are tracked in real time at the embedding vector layer and that bias is mathematically controlled via orthogonal projection algorithms fully proves compliance.
5.2 ISO/IEC 42001 Guideline Compliance and Immutable Reporting
To satisfy the control items of the ISO/IEC 42001:2023 (AI Management System) standard, the verification engine must automatically issue a high-dimensional bias scorecard of the entire internal dataset weekly or monthly. It must permanently preserve the matrix transformation history used for orthogonal projection in immutable storage along with pseudonymized compliance logs. This unalterable governance report serves as the ultimate legal shield to defend the enterprise from potential post-incident security disputes and AI unfairness litigation risks.
6. Embedding Model Bias Verification Practical Checklist for Data Security Engineers
To constantly diagnose weight integrity at the baseline of production RAG and LLM data pipelines and successfully anchor the geometric correction system, data architects must follow this 10-point technical checklist:
- Domain Target Set Definition: Have you explicitly defined the core attribute word and sentence sets (X, Y, A, B) in your business domain (HR, Finance, Tech) that risk distortion from universal model preconceptions?
- WEAT/SEAT Pipeline Scheduling: Is a scheduler job active to automatically calculate bias metrics (Effect Size d) during embedding model updates or bulk ingestion of new datasets?
- Bias Threshold Calibration: Have you established the optimal statistical threshold (e.g., $|d| \ge 0.8$) to dynamically trigger the geometric correction layer based on system accuracy and compliance targets?
- PCA-Based Subspace Extraction: Have you accurately extracted high-dimensional orthogonal basis vectors via Principal Component Analysis (PCA) targeting opposing context matrices to pinpoint the bias axis?
- Orthogonal Projection Middleware Deployment: Is the pipeline designed so that the orthogonal projection linear transformation is calculated seamlessly within the memory layer right after embedding conversion and right before Vector DB upsert?
- Business Fact Preservation Verification: Have you cross-verified that the company’s unique, legitimate statistics or factual data are not artificially warped or broken by comparing RAG search results before and after applying the correction matrix?
- HNSW Index Recall Evaluation: Have you benchmarked whether the vector coordinates slightly altered by orthogonal projection disrupt the vector database’s HNSW graph traversal efficiency and search recall?
- Correction Matrix Rotation: Do you have a mechanism to periodically recalculate and update the basis vectors forming the bias subspace to reflect trend updates in internal domain documents?
- Hybrid Reranking Multi-Space Integration: Is the system integrated with Part 3’s hybrid reranking algorithm to optimize the integrated scoring layer so that mathematically corrected vector search results achieve perfect synergy with traditional keyword (BM25) weights?
- Governance Audit Log Infrastructure: Are bias diagnostic statistics and correction matrix change histories recorded and preserved in an immutable log format to react instantly to regulatory due diligence?
Conclusion: The Pursuit of Data Objectivity Completes Ultimate AI Governance
While traditional data security focused on infrastructure controls—building high walls to keep out external intruders—Embedding Model Bias Verification is a domain of mathematical integrity preservation that identifies and rectifies the internal distortions of the technology we use.
In a vast high-dimensional geometric space where the curse and blessing of dimensionality intersect, using linear algebra to target external model preconceptions and flattening the space via orthogonal projection is the only key to pulling out an enterprise’s untarnished factual assets without distortion. When this refined weight verification guardrail is firmly embedded at the pipeline base, mass generative AI systems will finally shed the “black box” stigma and emerge as the most objective, dependable knowledge partners for the enterprise.
In our next deep dive, we will analyze the tenth and final topic of [The AI Shield] series: Honey-token Injection. We will examine a proactive trap design architecture that hardcodes fake, decoy embedding coordinates into highly sensitive zones within the vector database to instantly catch adversaries trying to conduct similarity extraction attacks for intellectual property exfiltration.
💡 Epilogue: Data Architect’s Practical Engineering Diary
Writing down these insights suddenly brings back vivid memories of my university days as a pure mathematics major, staring at abstract linear algebra and vector calculus textbooks while deeply stressing over how on earth these equations would help me earn a living. Back then, it felt like private academy tutoring or exam prep were the only practical career paths available to a math graduate.
However, standing here in 2026, where artificial intelligence and high-dimensional vector engineering dominate global infrastructure, I realize that the geometric concepts I spent tedious nights wrestling with—vector spaces, Principal Component Analysis (PCA), and orthogonal projection matrices—have become my most powerful weapons. They allow me to comprehend and design large-scale AI governance and security architectures dozens of times faster than others. Connecting those scattered pieces of past learning within completely unexpected macro trends is perhaps the greatest blessing an engineer can experience.
Combining this deep mathematical insight with practical infrastructure experience, I am officially launching a side project to build a Secure Mini-RAG System from scratch. Moving away from total reliance on commercial goliath LLMs, I will build a prototype prototype in a lightweight, open-source model environment to demonstrate exactly how the components we covered today—Embedding Noise Injection, atomic bitmask partitioning, and WEAT-based micro-bias correction layers—lock together perfectly in code. I look forward to sharing those engineering blueprints and production results with all of you soon.