Looking at recent security incidents, I find myself questioning whether this type of de-identification is truly necessary. Of course, the reason such incidents aren’t more frequent is precisely because we implement de-identification… Does de-identification affect service speed? I write this while wondering if this is another advancement made possible by hardware evolution. While it is a technology heavily utilized in production, it is also one that frequently draws criticism from business development departments.
In a Retrieval-Augmented Generation (RAG) architectural environment that couples Large Language Models (LLMs) with internal enterprise databases, storing raw Personally Identifiable Information (PII) inside a vector database triggers severe compliance violations of regulatory frameworks (such as PIPA in South Korea, GDPR, etc.). However, simply replacing all text with random noise or masking it creates a severe trade-off: it breaks semantic similarity calculations in the high-dimensional embedding space, drastically degrading document retrieval quality—the core feature of RAG.
The Vault module (internal/anonymizer/, internal/kms/), the data protection component of the Bastion-RAG framework, was engineered specifically to solve this dilemma by adopting a Deterministic De-identification technical specification. In an environment sharing the same key material, identical plaintext inputs always generate unique, consistent tokens that can be matched, thereby preserving semantic Join operations and contextual integrity within the vector space.
This post provides a clean analysis of the two-phase (Phase 1, Phase 2) processing pipeline structure of the Vault module and the detailed source code implementation specifications of its eight core de-identification strategy interfaces.

URL Site > https://github.com/zafrem/bastion-vault
Series Name: Bastion – Project Security RAG
- [Bastion-RAG] Project Security RAG
- [Bastion-RAG 0] Get help from AI (Architecture Design)
- [Bastion-RAG 1 – Sentinel]
- [Bastion-RAG 2 – Vault]
- Multi-tenancy
- Deterministic De-identification – Here!
- [Bastion-RAG 3 – Navigator]
- Hybrid Reranking
- Logical Partitioning
- [Bastion-RAG 4 – Archor]
- Embedding Noise Injection
- Embedding Model Bias Verification
- [Bastion-RAG 5 – Tracker]
- Data Lineage Tracking
- Honey-token Injection
- [Bastion-RAG Demo]
Table of Contents
1. Technical Imperatives for Deterministic Processing in RAG
Applying random tokenization techniques that lack consistency (determinism) during the de-identification process introduces the following fatal structural flaws into the RAG system’s data flow:
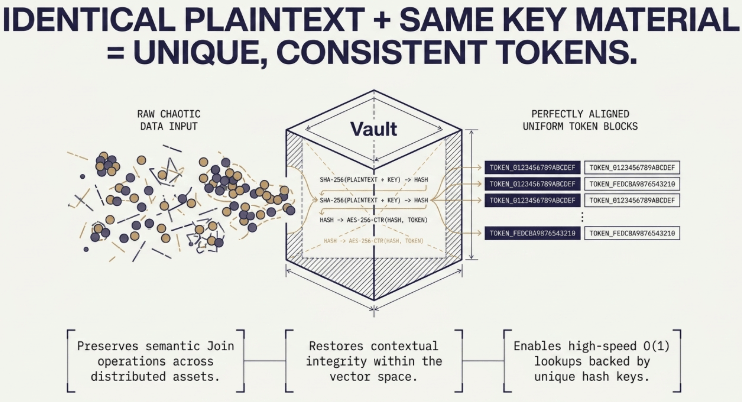
- Destruction of Embedding and Matching Spaces: If a direct identifier like an individual’s name inside a document chunk is replaced with
TOK_Aduring data ingestion, but the same name within a real-time query is randomly swapped withTOK_B, their cosine similarity within the dense vector space will evaluate as entirely unrelated. This effectively neutralizes the vector index and prevents relevant context from being retrieved. - Loss of Relational Data Joins: In scenarios where distributed document assets must cross-reference tables (e.g., linking a customer order to a service ticket) via tokenized identifiers to expand semantic context, any mismatch between tenant identification tokens completely severs the relational link.
- Phase 2 Reversal Operation Overhead Control: When securely reversing tokens back to plain text (Selective Detokenization) after passing through the LLM, a non-deterministic approach requires scanning the entire global registry, introducing a massive performance bottleneck of $O(N)$ or greater. A deterministic structure guarantees high-speed $O(1)$ lookups backed by unique hash keys.
However, deterministic de-identification remains vulnerable to frequency analysis attacks on low-cardinality fields (such as gender or blood type). To address this, the Vault module deploys a blended architecture that dynamically routes data through one-way HMAC-SHA256, symmetric key encryption, or reversible tokenization based on the field’s underlying sensitivity classification tier (L1 to L5).
2. Strategy Interface and Injected Parameter Schema
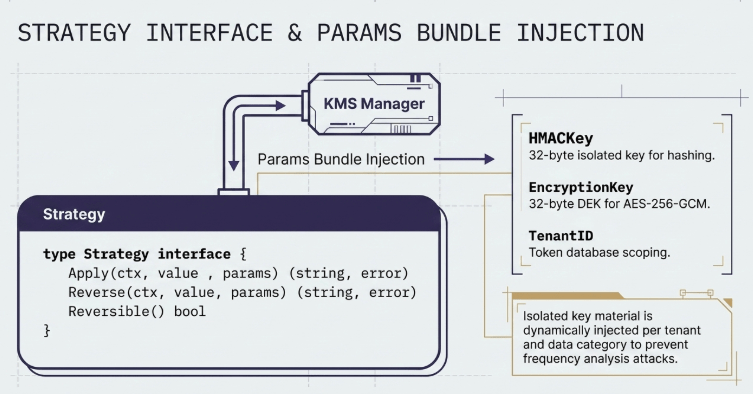
Every de-identification technique housed within the Vault architecture is compiled to enforce a single Strategy interface, ensuring modular maintainability and stand-alone usability.
Go
// internal/anonymizer/strategies/strategy.go
type Strategy interface {
// Apply transforms a plaintext value into its de-identified token form according to architectural rules.
Apply(ctx context.Context, value string, params Params) (string, error)
// Reverse reconstructs the token back to plain text, provided Reversible() evaluates to true.
Reverse(ctx context.Context, value string, params Params) (string, error)
// Name returns the static strategy identifier recorded in audit logs.
Name() string
// Reversible reports whether this strategy can physically or logically reverse the transformation.
Reversible() bool
}
When the Apply or Reverse methods execute within a strategy, an external Key Management Service (KMS) manager automatically resolves and dynamically injects isolated key material and contextual field hints scoped per tenant and data category via a structured Params bundle.
Go
// internal/anonymizer/strategies/strategy.go
type Params struct {
HMACKey []byte // 32-byte isolated key for deterministic tokenization and one-way hashes
EncryptionKey []byte // 32-byte DEK used for AES-256-GCM symmetric encryption
MaskPattern string // Override string to control partial masking field formats
GeneralizationLevel int // Abstraction depth (0=plaintext, higher values imply broader generalization)
Domain string // Extra domain context, such as retaining an email domain suffix
FieldHint string // Structural field identifier used for routing range generalizations
TenantID string // Tenant token used to scope lookups inside the token database registry
}
3. Implementation Specifications for Vault’s Core Anonymization Strategies
The low-level technical specifications governing the core engines statically bound within the Vault processing pipeline (internal/anonymizer/strategies/) are detailed below:
3.1 Reversible Tokenization (deterministic_tokenization)
- Reversible: Yes (requires a live
tokendb.Storeregistry mapping) - Target Fields: Names, email addresses, employee IDs
The engine computes a unique 32-byte binary digest using HMAC-SHA256, normalizes it via URL-safe Base64 encoding, and truncates it to 22 characters. A TOK: prefix is appended to prevent downstream components from mistaking the token for raw plaintext.
Go
// internal/anonymizer/strategies/tokenization.go
func (s *TokenizationStrategy) Apply(ctx context.Context, value string, p Params) (string, error) {
if len(p.HMACKey) == 0 {
return "", fmt.Errorf("tokenization: HMAC key required")
}
mac := hmac.New(sha256.New, p.HMACKey)
mac.Write([]byte(value))
sum := mac.Sum(nil)
token := base64.RawURLEncoding.EncodeToString(sum)
if len(token) > 22 {
token = token[:22]
}
tok := "TOK:" + token
// Synchronously persist the token-to-plaintext pair to the registry for Phase 2 reversal
if s.store != nil {
entry := tokendb.Entry{
Token: token,
Original: value,
TenantID: p.TenantID,
PIIType: p.FieldHint,
CreatedAt: time.Now().UTC(),
}
_ = s.store.Put(ctx, entry)
}
return tok, nil
}
3.2 HMAC One-Way Hashing (hmac_sha256)
- Reversible: No
- Target Fields: Resident Registration Numbers (RRN) / Government Identifiers
This strategy is deployed to completely neutralize high-sensitivity L1 Direct Identifier fields. Because standardized identifiers possess constrained structural patterns that are vulnerable to offline brute-force dictionary lookups, a plain un-salted hash is prohibited. The engine combines a tenant-isolated HMACKey and maps the full 64-character hex digest alongside an HMAC: prefix.
Go
// internal/anonymizer/strategies/hmac.go
func (s *HMACStrategy) Apply(_ context.Context, value string, p Params) (string, error) {
if len(p.HMACKey) == 0 {
return "", fmt.Errorf("hmac_sha256: HMAC key required")
}
mac := hmac.New(sha256.New, p.HMACKey)
mac.Write([]byte(value))
return "HMAC:" + hex.EncodeToString(mac.Sum(nil)), nil
}
3.3 Partial Masking (partial_masking)
- Reversible: No
- Target Fields: Mobile phone numbers, credit card numbers
To preserve static readability for structural data validation, intermediate character strings are permanently swapped with wildcard (*) characters.
Go
// internal/anonymizer/strategies/masking.go
func maskMobile(v string) string {
digits := stripNonDigits(v) // Extract and clean numeric symbols only
if len(digits) < 10 {
return strings.Repeat("*", utf8.RuneCountInString(v))
}
return digits[:3] + "-****-" + digits[len(digits)-4:]
}
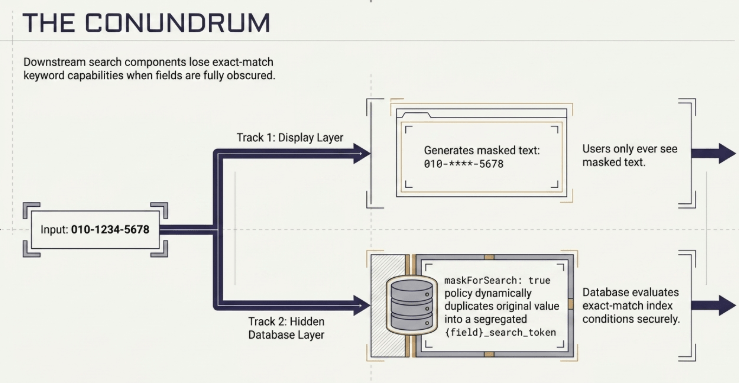
For fields like phone numbers, while the display text is masked (e.g., 010-****-5678), the underlying routing framework splits execution into a parallel track if a maskForSearch flag is enabled. This generates an additional exact-match lookup token (_search_token) alongside the masked entry.
3.4 Symmetric Key Encryption (encryption)
- Reversible: Yes (requires authorized KMS master key decryption privileges)
- Target Fields: Salary metrics, financial asset values
To satisfy both confidentiality and baseline data integrity verification, the engine mandates authenticated symmetric encryption using AES-256-GCM. To neutralize replay vulnerabilities, every single encryption operation generates a unique, cryptographically random 12-byte nonce that is prepended directly to the head of the final binary payload slice.
Go
// internal/anonymizer/strategies/encryption.go
func gcmEncrypt(key, plaintext []byte) ([]byte, error) {
block, _ := aes.NewCipher(key)
gcm, _ := cipher.NewGCM(block)
nonce := make([]byte, gcm.NonceSize()) // Generate a 12-byte cryptographic random number
if _, err := io.ReadFull(rand.Reader, nonce); err != nil {
return nil, err
}
// Seal data directly into the nonce buffer to construct a [Nonce 12B][Ciphertext][Tag 16B] topology
return gcm.Seal(nonce, nonce, plaintext, nil), nil
}
The Reverse decryption routine extracts the 12-byte nonce header after dropping the ENC: prefix. If even a single bit of the incoming ciphertext is corrupted or truncated, the GCM authentication tag verification fails, halting data processing immediately.
3.5 Regional Generalization (generalization)
- Reversible: No
- Target Fields: Regional addresses, city identifiers
This strategy truncates explicit geographic indicators, abstracting text into broader demographic regions. In compliance with structural administrative hierarchy rules, lower-tier tokens are permanently pruned from the string array based on the configured depth level.
Go
// internal/anonymizer/strategies/generalization.go
func generalizeRegion(value string, level int) string {
parts := strings.Fields(value)
if len(parts) == 0 { return "" }
// Level 1: Permanently strip fine-grained neighborhood suffixes
if level >= 1 {
last := parts[len(parts)-1]
if strings.HasSuffix(last, "동") || strings.HasSuffix(last, "로") || strings.HasSuffix(last, "길") {
parts = parts[:len(parts)-1]
}
}
// Level 2: Sequentially prune localized district parameters
if level >= 2 && len(parts) > 0 {
last := parts[len(parts)-1]
if strings.HasSuffix(last, "구") || strings.HasSuffix(last, "군") {
parts = parts[:len(parts)-1]
}
}
return strings.Join(parts, " ")
}
Through this layer, specific source strings map to broad, generalized clusters, allowing the RAG data space to group records without leaking precision.
3.6 Numeric and Temporal Range Generalization (range_generalization)
- Reversible: No
- Target Fields: Birth dates, precise age metrics, salary ranges
The engine references the FieldHint identifier to evaluate the semantic category of a data point, subsequently bucketizing values into calculated intervals.
Go
// internal/anonymizer/strategies/generalization.go
func generalizeDateToDecade(value string) (string, error) {
parts := strings.Split(strings.ReplaceAll(value, "/", "-"), "-")
year, _ := strconv.Atoi(parts[0][:4])
decade := (year / 10) * 10 // Drop integer accuracy to compress values into a 10-year generation bracket
return fmt.Sprintf("%ds", decade), nil
}
A specific birth date payload passes through this processing loop to converge into a static "1980s" string literal, mitigating re-identification risks.
3.7 Complete Suppression (suppression)
- Reversible: No
- Target Fields: Detailed street addresses, specific facility or building numbers
Adhering strictly to the core principle of data minimization, this strategy completely obliterates highly granular text fields where partial leakage could facilitate inference alignment or composition attacks. The original string content is bypassed entirely, and a static token placeholder ([REMOVED]) is returned without initiating memory read allocations.
Go
// internal/anonymizer/strategies/suppression.go
const suppressionPlaceholder = "[REMOVED]"
func (s *SuppressionStrategy) Apply(_ context.Context, _ string, _ Params) (string, error) {
return suppressionPlaceholder, nil
}
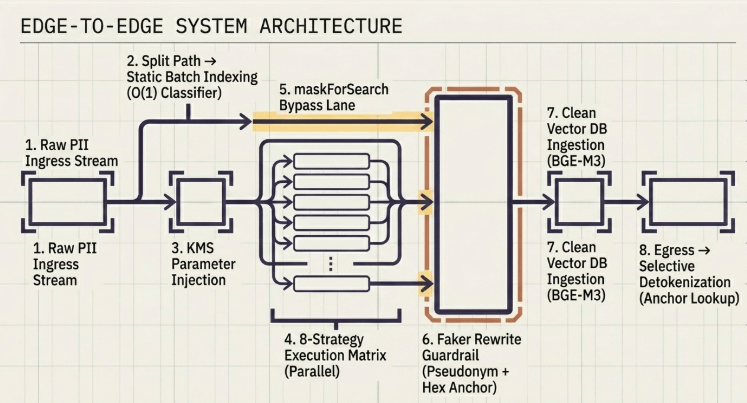
4. Pipeline Execution Architecture and Batch Performance Optimizations
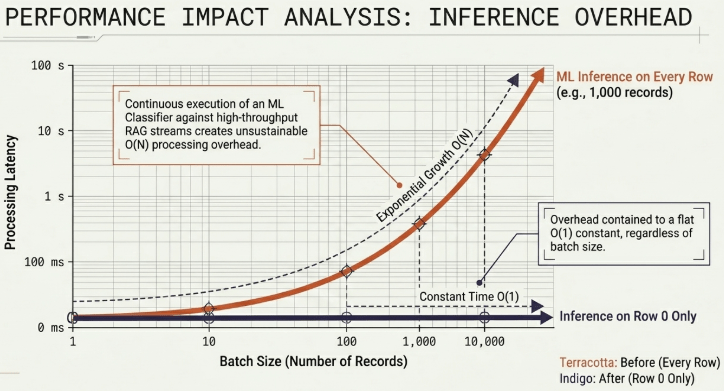
Continuously executing a machine learning classification engine (Classifier) against every single record inside a real-time, high-throughput RAG ingress stream creates unsustainable processing overhead. To eliminate this latency bottleneck, the Vault engine leverages a split Two-Phase Batch Transformation Pipeline.
Raw Batch Records Collection (Max 1,000 units)
│
▼
[Phase 1: Sampling & Detection Indexing] ← Single-row inference to derive rule definitions (O(1))
│
▼
[KMS Token Infrastructure Mapping] ← Binds hmacKey and encKey once per incoming batch
│
▼
[Phase 2: Matrix Parallel Transformation] ← Loops records to execute core anonymization maps
│
├───► maskForSearch == true ? ───────► Replicates and injects high-speed {field}_search_tokens
│
[Audit Governance Signing Logs] ← Generates continuous append-only signed JSONL entries
│
▼
Anonymized Response Package Payload
4.1 Static Ingress Index Sampling for Overhead Containment
Operating under the structural paradigm that all record items bundled within a single transaction collection maintain identical schema layouts, the buildDetectionIndex() routine isolates machine learning inference exclusively to the initial batch entry (Index 0).
Go
// internal/anonymizer/engine.go
func (e *Engine) buildDetectionIndex(records []map[string]any, policies []fieldPolicy) map[string]fieldPolicy {
index := make(map[string]fieldPolicy)
if len(records) == 0 { return index }
// Isolate PII classification exclusively to the very first index row entry
detections := e.classifier.DetectPII(records[0])
for _, det := range detections {
for _, pol := range policies {
if pol.piiType == det.PIIType {
index[det.Field] = pol // Map field keys into a static O(1) rule index template
break
}
}
}
return index
}
The remaining records (up to 1,000 entries per batch payload) bypass the classifier entirely, inheriting the compiled rule definitions to complete instantaneous key lookups. This optimization confines heavy classification overhead to a flat $O(1)$ constant footprint across the transaction life cycle.
4.2 Hybrid Search Compliance via maskForSearch Token Replication
A core challenge within secure RAG routing paths is handling exact-match string queries against fields that have undergone total text masking (e.g., hidden telephone numbers or national identification keys). Because the underlying index structures are fully obscured, downstream search components lose keyword query capabilities.
To resolve this limitation, the transformRecord subroutine dynamically intercepts fields containing a maskForSearch: true policy flag. Alongside the masked display record (e.g., mobile: "010-****-5678"), the engine duplicates the original value into a segregated background field: {field}_search_token. This approach satisfies enterprise-level search capabilities by allowing the database to track and evaluate exact-match index conditions while ensuring users are only exposed to masked text.
5. Architectural Synergy: Faker Rewrite Guardrails and Embedding Integrity
When Phase 1 de-identification is completed, the output strings represent high-entropy cryptographic strings (e.g., TOK:RjIzbTYxdmVBcFVNVVhi).
Passing these opaque strings directly into downstream search layers and high-performance multilingual embedding models (e.g., BGE-M3) degrades retrieval performance. Because modern open-source embeddings are optimized for linguistic contexts and natural phrase topologies, unstructured high-entropy strings skew vector weights, scattering coordinates and degrading similarity lookup accuracy.
To eliminate this structural decay, the pipeline activates a Faker Rewrite Guardrail immediately prior to handing over the context to the Navigator interface.
- Contextual Natural Language Synthesis: The
TokenRewritercomponent traps high-entropy strings and dynamically maps them to syntactically clean, contextual pseudonyms (e.g., translating a raw token string into a natural, readable name like"James Anderson"). - Reversal Anchor Preservation: The engine isolates the initial 6 hex characters of the original cryptographic token and appends it to the tail of the fake string as an immutable tracking anchor (e.g.,
"James Anderson_RjIzbT").
This architectural synergy allows downstream embedding processors to ingest perfectly formatted natural phrases, preserving dense vector spatial distributions. During Phase 2 read operations, the egress engine extracts the 6-character hex anchor from the string tail, using it as an $O(1)$ index key to reverse pseudonyms back to plain text without structural data loss.
6. Conclusion: Achieving Security and Performance Equilibrium
Architecting the deterministic de-identification pipeline inside [Bastion-RAG 2 - Vault] was an exercise in balancing strict corporate governance with real-world infrastructure constraints. By rejecting simplistic masking paradigms and deploying an 8-stage algorithmic strategy matched to down-stream machine learning workloads, the architecture eliminates processing friction.
The combination of single-row batch index sampling, hybrid maskForSearch token replication, and Faker rewrite loops restricts the entire pseudonymization processing budget to under 5 milliseconds for latency targets. For Chief Information Security Officers (CISOs) and Principal AI Engineers seeking to secure corporate data assets without compromising vector precision or search relevance, this deterministic specification provides a production-hardened blueprint for zero-trust RAG operations.