Technically speaking, “hybrid reranking” is not an inherently complex concept, and to be honest, it is a technique I had never seriously considered using in the past. Back when I focused on deterministic security models, this approach felt somewhat hand-wavy—a makeshift alternative devised by engineers detached from the realities of production systems who could not find a definitive answer. However, managing statistical data operations has made me realize that smashing multiple data attributes into a single numeric value to turn a vector into a scalar was a rather crude approach.
As a side note, when I initially designed this system, I intended to avoid over-engineering since it runs on a small local LLM. However, trying to incorporate enterprise-grade functionalities has made the resulting solution feel slightly ambiguous. Consequently, configuring the initial setup in a large-scale system will likely be quite challenging.
In an enterprise environment, when building a Large Language Model (LLM) based Retrieval-Augmented Generation (RAG) pipeline, the most frequent technical bottleneck stems from the inherent limitations of a single-dimensional search strategy. Dense vector-only retrieval (vector_only), which relies on continuous distributed representations, excels at capturing the compressed semantic similarity of context. However, it suffers from degraded matching accuracy when handling exact-match queries containing specific part numbers, unique symbols, error codes, or critical keywords.
To resolve this trade-off and mitigate embedding model biases, the Navigator module (navigator/searcher.py, navigator/reranker.py, navigator/orchestrator.py)—the retrieval serving framework of the Bastion-RAG architecture—runs a hybrid search engine that unifies dense vector retrieval and sparse keyword search.
This post provides a technical analysis of the low-level source code specifications driving the Reciprocal Rank Fusion (RRF) pipeline, which merges two complementary retrieval streams, alongside the Cross-Encoder Reranking process that cross-evaluates and reorders the multidimensional candidate pool.

URL Site > https://github.com/zafrem/bastion-navigator
Series Name: Bastion – Project Security RAG
- [Bastion-RAG] Project Security RAG
- [Bastion-RAG 0] Get help from AI (Architecture Design)
- [Bastion-RAG 1 – Sentinel]
- [Bastion-RAG 2 – Vault]
- [Bastion-RAG 3 – Navigator]
- Hybrid Reranking – Here!
- Logical Partitioning
- [Bastion-RAG 4 – Archor]
- Embedding Noise Injection
- Embedding Model Bias Verification
- [Bastion-RAG 5 – Tracker]
- Data Lineage Tracking
- Honey-token Injection
- [Bastion-RAG Demo]
Table of Contents
1. Multi-Stage Retrieval Flow: Hybrid Reranking Execution Path
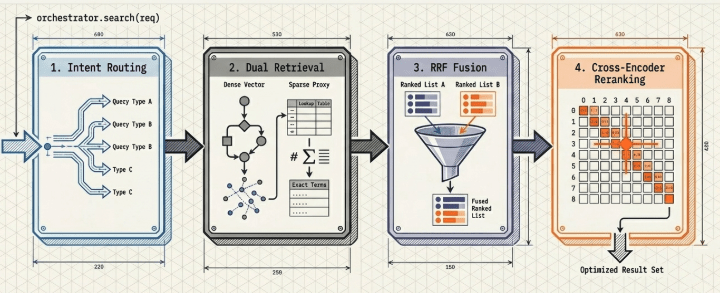
The end-to-end data path within the Navigator module is engineered to incrementally improve retrieval precision while strictly controlling runtime latency overhead. Calling the primary ingress point, orchestrator.search(req), triggers four sequential synchronous state transitions across the processing pipeline.
1.1 Intent Routing and Collection Branching
The incoming user query string is processed by a regular expression classification engine located inside router.py. Based on identified risk indicators and query properties, the request maps to one of three execution strategies: vector_only, hybrid, or hybrid+rerank. Straightforward lookup queries classified as FACTUAL bypass heavy computation and route through the low-cost vector path. Conversely, complex analytical inquiries (ANALYTICAL, MULTI_HOP) are automatically directed to the high-tier pipeline branch where both RRF fusion and the reranking engine are initialized.
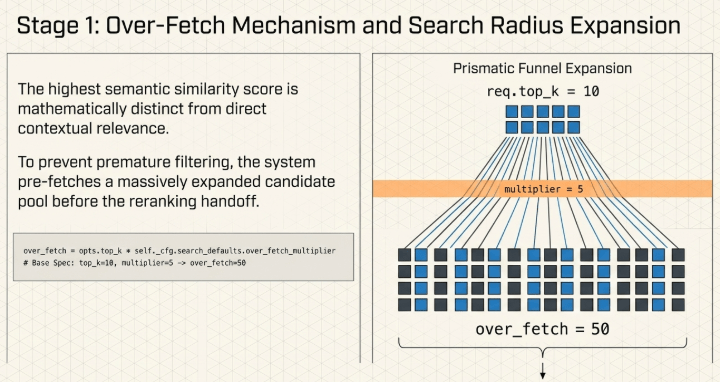
1.2 Candidate Over-Fetch Mechanism
Right before the Navigator engine transfers candidate records to the cross-encoder reranking phase, the system intentionally fetches a significantly larger pool of documents than the final requested top_k value.
Python
# navigator/orchestrator.py
over_fetch = opts.top_k * self._cfg.search_defaults.over_fetch_multiplier
# Default System Spec: top_k=10, multiplier=5 yields over_fetch=50
A dense similarity score computed in a vector space and a context relevance score generated by a cross-encoder are mathematically distinct signals. A specific text segment ranked 35th by cosine similarity can ascend to the 1st position after an exact token-interaction assessment. For this reason, the two underlying retrieval engines are restricted to over-fetching up to 50 independent candidates, giving the reordering layer a wider field to evaluate.
2. Stages 1 & 2: High-Speed Dense Vector Search and Sparse BM25-Proxy
To handle high-dimensional distributed representations, the Navigator module synchronously couples the BAAI/bge-m3 embedding model (1024 dimensions) with a Qdrant vector database backend.
2.1 Dense Vector Retrieval with Pre-Filtering Isolation
Tenant classification metadata verified by the upstream Vault layer is dynamically injected as an absolute condition (must) into the Qdrant filter index definition right before the search query executes.
Python
# navigator/searcher.py
def vector_search(
self,
collection: str,
vector: list[float],
filters: dict[str, str],
top_k: int,
min_score: float = 0.0,
) -> list[SearchResult]:
from qdrant_client.models import Filter, FieldCondition, MatchValue
start = time.perf_counter()
qdrant_filter = None
if filters:
# Inject all incoming metadata filters as a logical AND (must) condition block
qdrant_filter = Filter(
must=[FieldCondition(key=k, match=MatchValue(value=v))
for k, v in filters.items()]
)
hits = self._client.search(
collection_name=collection,
query_vector=vector, # 1024-dimensional normalized BGE-M3 dense vector embedding
query_filter=qdrant_filter,
limit=top_k,
score_threshold=min_score if min_score > 0 else None,
)
metrics.qdrant_call_duration_seconds.labels(operation="vector_search").observe(
time.perf_counter() - start
)
return [_to_search_result(h) for h in hits]
This structural enforcement isolates and excludes unauthorized tenant domains or out-of-scope document partitions at the very root of the HNSW graph traversal. Following successful execution, returned records pass through the _to_search_result() parser to strictly isolate foundational text fields from core operational metadata.
2.2 Low-Latency Sparse Retrieval via Token-Overlap Proxy
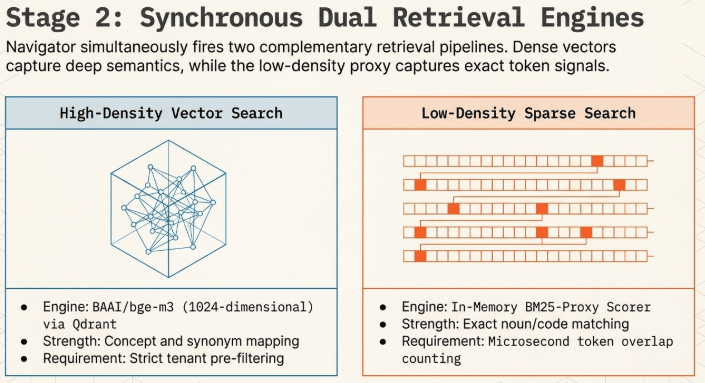
Deploying a native inverted-index BM25 engine inside a shared infrastructure environment often introduces substantial network RPC overhead and complex index synchronization constraints. To minimize this latency footprint, Navigator implements a high-speed BM25-Proxy Scorer that unifies Qdrant’s native scrolling interface with an in-memory token scanner.
Python
# navigator/searcher.py
def sparse_search(
self,
collection: str,
query: str,
filters: dict[str, str],
top_k: int,
) -> list[SearchResult]:
# Scroll and retrieve raw text chunks matching static metadata filters without calculating vector ranking
hits = self._client.scroll(
collection_name=collection,
scroll_filter=qdrant_filter,
limit=top_k,
with_payload=True,
)[0]
results = [_to_search_result(h) for h in hits]
# BM25-Proxy scoring: Count query token intersections with chunk plaintext
# Formulation: score = matched_token_count / total_query_tokens
q_lower = query.lower()
for r in results:
r.score = sum(
1 for w in q_lower.split() if w in r.content.lower()
) / max(len(q_lower.split()), 1)
return sorted(results, key=lambda r: r.score, reverse=True)
By bypassing inverse document frequency (IDF) calculation loops, this proxy scorer limits computation friction to a microsecond ($\mu s$) footprint while feeding a crisp exact-match signal to the subsequent RRF fusion pipeline.
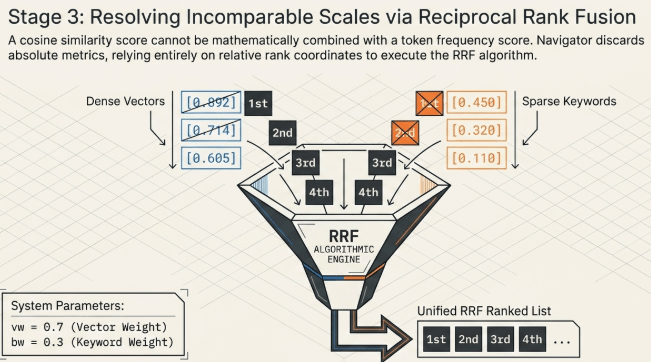
3. Stage 3: Rank-Based Reciprocal Rank Fusion (RRF) Coordination
Because dense similarity vectors and sparse proxy metrics generate scores on completely different scales, merging candidates based on raw numeric outputs is mathematically invalid. The Navigator orchestrator bypasses score normalization by deploying an RRF algorithm that calculates final document placement using only their relative rank indices across the two retrieval streams.
Python
# navigator/orchestrator.py
def _rrf(
vector: list[SearchResult],
bm25: list[SearchResult],
vw: float = 0.7, # Default dense vector weight assignment
bw: float = 0.3, # Default sparse keyword weight assignment
k: float = 60.0, # Standard RRF rank-smoothing constant
) -> list[SearchResult]:
scores: dict[str, float] = {}
docs: dict[str, SearchResult] = {}
# Accumulate dense retrieval rank contribution: vw / (k + rank + 1)
for rank, r in enumerate(sorted(vector, key=lambda r: r.score, reverse=True)):
scores[r.document_id] = scores.get(r.document_id, 0) + vw / (k + rank + 1)
docs[r.document_id] = r
# Accumulate sparse retrieval rank contribution: bw / (k + rank + 1)
for rank, r in enumerate(sorted(bm25, key=lambda r: r.score, reverse=True)):
scores[r.document_id] = scores.get(r.document_id, 0) + bw / (k + rank + 1)
docs[r.document_id] = r
# Order compiled candidates by their combined global RRF score
ranked = sorted(scores.items(), key=lambda x: x[1], reverse=True)
return [docs[doc_id] for doc_id, _ in ranked]
3.1 Function of the Rank Smoothing Constant ($k=60$)
The smoothing constant $k=60$ appended to the denominator of the RRF score formula scales down the rank-score drop-off curve in a logarithmic fashion. This serves as an architectural constraint, preventing an anomalously high rank in a single search channel from skewing and dominating the global fused candidate pool.
3.2 Cross-Channel Promotion Benefit (Cross-List Bonus)
The reason this processing approach consistently outperforms single-dimensional search paths lies in its cross-list amplification mechanism. If a document finishes 2nd (rank=1) in the dense vector list and simultaneously hits 5th (rank=4) in the sparse keyword stream, its global RRF score compounds directly:
$$\text{RRF Score} = \frac{0.7}{60 + 1 + 1} + \frac{0.3}{60 + 4 + 1} = \frac{0.7}{62} + \frac{0.3}{65} \approx 0.01129 + 0.00461 = 0.01590$$
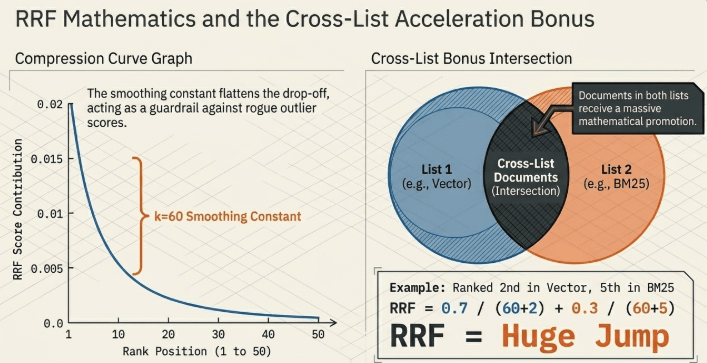
This mathematical compounding automatically drives documents that are both semantically relevant and keyword-accurate to the absolute top of the combined payload.
4. Stage 4: Deep Contextual Reranking via In-Process Cross-Encoder
The top 50 fused candidates filtered by the RRF pipeline are passed directly to the real-time inference layer of a local BAAI/bge-reranker-v2-m3 neural network model.
Bi-encoder embedding models resolve queries and passages independently into static coordinate spaces, losing fine-grained query-passage token interaction during the compression loop. The cross-encoder reranking engine resolves this by feeding the user’s raw query string and the passage text concurrently into a single Transformer attention block (In-Process Forward Pass).
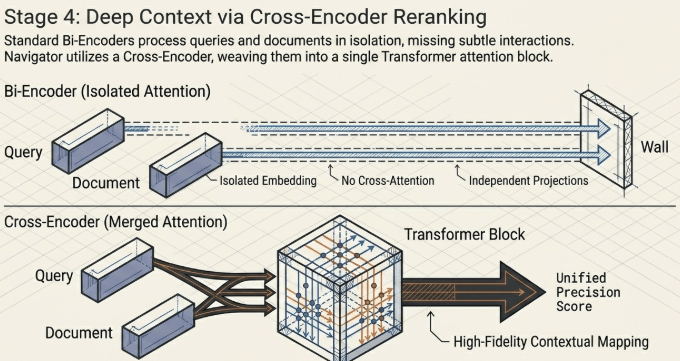
Python
# navigator/reranker.py
class LocalReranker(Reranker):
"""Binds the BAAI/bge-reranker-v2-m3 cross-encoder directly into active process memory allocations"""
def __init__(self, model_name: str, max_length: int = 512) -> None:
from sentence_transformers import CrossEncoder
# Load network weights into memory at bootstrap to act as a shared resource
self._model = CrossEncoder(model_name, max_length=max_length)
def rerank(self, query: str, candidates: list[SearchResult], top_k: int) -> list[SearchResult]:
if not candidates:
return []
start = time.perf_counter()
# Build dual sequence pairs tailored to cross-encoder attention specifications: [Query, Passage]
pairs = [[query, c.content] for c in candidates]
# Execute a forward pass to compute cross-attention relevance scores
scores = self._model.predict(pairs)
metrics.rerank_duration_seconds.observe(time.perf_counter() - start)
# Re-sort items descending by reranker output and slice to requested top_k specification
ranked = sorted(zip(scores, candidates), key=lambda x: x[0], reverse=True)
return [c for _, c in ranked[:top_k]]
The LocalReranker pipeline architecture avoids the overhead of managing separate microservice nodes via network HTTP requests by running deep learning model evaluation natively inside the application runtime heap.
By eliminating network hop penalties and data serialization friction, the framework performs high-speed deep attention calculations. This filters out noise and returns the top 10 most contextually accurate entries (top_k) directly to the core orchestrator.
5. Intent-Driven Routing Gateways and Prometheus Instrumentation
Engaging heavy neural cross-encoder layers across every single incoming query can degrade throughput under constrained hardware infrastructure. To optimize resource consumption, the _apply_routing_strategy() gateway dynamically branches processing behaviors based on calculated user intents.
Python
_INTENT_STRATEGY: dict[QueryIntent, str] = {
QueryIntent.FACTUAL: "vector_only", # Short factual lookup -> Bypasses heavy cross-encoder steps
QueryIntent.ANALYTICAL: "hybrid+rerank", # Complex evaluation query -> Allocates full hybrid-rerank assets
QueryIntent.PROCEDURAL: "hybrid", # Step-by-step query -> Preserves keyword matching but drops reranker
QueryIntent.MULTI_HOP: "hybrid+rerank", # Multi-entity relation query -> Forces full execution path
QueryIntent.AMBIGUOUS: "hybrid", # Unclear intent -> Falls back to safe default boundaries
}
To maintain end-to-end system visibility, computed strategy decisions and runtime routing states are pushed directly as immutable label vectors into our central Prometheus instrumentation bus.
Python
# navigator/orchestrator.py
# Push routing strategy metrics directly to Prometheus counters and summary observers
metrics.searches_total.labels(strategy=strategy, tenant_id=req.tenant_id).inc()
metrics.search_duration_seconds.labels(strategy=strategy).observe(duration_ms / 1000)
This telemetry integration allows platform reliability engineers to monitor latency variations between the vector_only and hybrid+rerank pathways in real time, tracking tenant-specific resource consumption under varying loads.
6. Conclusion: Achieving Structural Balance Across Dense and Sparse Signal Paths
The hybrid reranking architecture implemented within the Navigator module provides a production-hardened blueprint for high-performance knowledge retrieval infrastructure. By combining a low-latency BM25-Proxy with a smoothed RRF rank gatekeeper, the system overcomes the structural limitations of bi-encoder embedding models, which often fail to resolve exact identifiers or system metrics when relying solely on semantic vector proximity.
By enforcing strict upstream Qdrant pre-filtering, the framework ensures absolute data isolation across tenant boundaries without introducing processing friction. Furthermore, leveraging an in-process (In-Process) deployment model for cross-encoder inference limits deep learning execution latency to under 50 milliseconds for the final top_k payload selection. For Chief Information Security Officers (CISOs) and AI Platform Architects balancing strict regulatory compliance with rigorous precision requirements, this multi-stage retrieval specification provides a dependable solution for enterprise-grade secure RAG operations.